








Top 5 Community Tools Every DevRel Should Have for Building a Thriving Developer Community
Discover the top 5 community tools every DevRel needs! From community management platforms to content creation tools, this guide...
Docker Volumes: Key Features and Benefits for Data Management
Docker volumes is an extensive feature of Docker that allows data to be stored and managed persistently. The volumes...
Dagger: Develop your CI/CD pipelines as code
Our traditional CI/CD tools are usually rigid and have predefined workflows that make customization limited. They require an extensive...
Monitoring Containerd
Learn the importance of monitoring Containerd, its architecture, and tools for tracking performance, resource utilization, and health for efficient...
Is Kubernetes ready for AI
Unleash the power of AI with Kubernetes! Explore its compatibility, advantages, and potential as the ultimate solution for AI...
How to Download and Install Kubernetes
Kubernetes has become the de facto standard for container orchestration, providing a scalable and resilient platform for managing containerized...
Why does AI need GPU?
Artificial intelligence and machine learning are amazing technologies that can do incredible things like understand human speech, recognize faces...
Smart Money in Smart Technology: Investing in Large IoT Projects
Explore the world of large IoT projects, their benefits, risks, and key considerations for investors. Learn how to invest...All Stories

How To Remove Search Marquis on a Mac?
Search Marquis is very similar to the Bing redirect virus, it’s actually an upgraded version. The problem with it is it...
Highlights of the Docker and Wasm Day Community Meetup Event
The Docker Bangalore and Collabnix (Wasm) communities converged at the Microsoft Reactor Office for a groundbreaking meetup that explored the fusion...
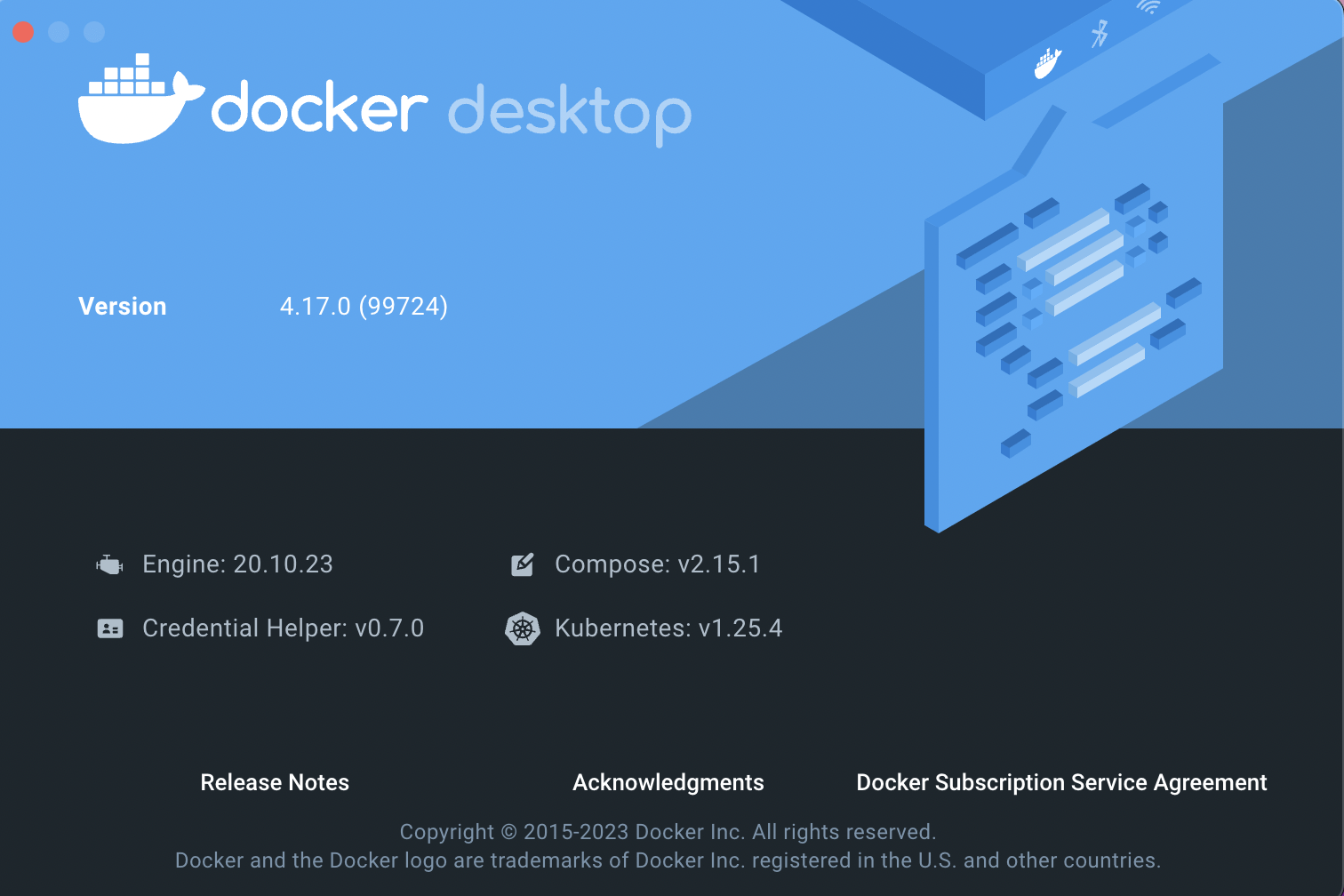
Kubernetes on Docker Desktop in 2 Minutes
Docker Desktop is the easiest way to run Kubernetes on your local machine – it gives you a fully certified Kubernetes cluster...
Docker System Prune: Cleaning Up Your Docker Environment
Docker has revolutionized how software applications are developed, deployed, and run. Containers provide a consistent environment for applications, making them portable...
The Role of Brokers in Financial Markets: A Comprehensive Guide
In the vast and complex world of financial markets, brokers play a crucial role in facilitating transactions between buyers and sellers....
Top 20 companies that uses Wasm
WebAssembly (Wasm) is a binary instruction format designed to be as efficient as native machine code. It is being used by...

Docker Dev Tools: Turbocharge Your Workflow!
In today’s rapidly evolving development landscape, maximizing productivity and streamlining workflows are paramount. Docker, with its cutting-edge developer tools, presents an...
What is Real-Time Data Warehousing? A Comprehensive Guide
Organizations are always attempting to extract meaningful insights from their data in real time to influence choices and preserve a competitive...
Announcing the Meetup Event – Container Security Monitoring for Developers using Docker Scout
There are various security tools available today in the market. While there are similarities and differences between all tools of this...
The State of Docker Adoption for AI/ML
Artificial intelligence (AI) and machine learning (ML) are now part of many applications, and this trend is only going to continue....
How to Monitor Node Health in Kubernetes using Node Problem Detector Tool?
Kubernetes is a powerful container orchestration platform that allows users to deploy and manage containerized applications efficiently. However, the health of...
Building a Multi-Tenant Machine Learning Platform on Kubernetes
Machine learning platforms are the backbone of the modern data-driven enterprises. They help organizations to streamline their data science workflows and...
Enhancing Business Efficiency through Streamlined Document Management and Collaboration in Virtual Data Room
Did you know that employee productivity has skyrocketed by 61.8% between 1979 and 2020? That’s incredible! And a big part of...
Implementing Automated RDS Backup and Restore Strategy with Terraform
In today’s fast-paced digital world, data protection and business continuity are of paramount importance. For organizations leveraging Amazon RDS (Relational Database...
How to Fix “Cannot connect to the Docker daemon at unix:/var/run/docker.sock” Error Message?
Docker is a popular platform for building, shipping, and running applications in containers. However, sometimes when you try to run Docker...
Rate Limiting in Redis Explained
Rate limiting is a crucial mechanism used to control the flow of incoming requests and protect web applications and APIs from...
How to Integrate Docker Scout with GitHub Actions
Docker Scout is a collection of software supply chain features that provide insights into the composition and security of container images. It...
The Shift to Virtual Boardrooms: Leveraging Technology for Remote Collaboration and Decision-Making
It's remarkable how boardroom portals have transformed the world. Get acquainted with this technology as well.
Infrastructure as Code (IaC): Navigating the Future of DevOps Tools and Education
In the ever-evolving world of technology, the concept of Infrastructure as Code (IaC) has become an indispensable part of DevOps practices....
Seamless Integration with Tomorrow.io Weather API:Enhance Your App’s Weather Experience
Integrating weather data into your application can significantly enhance its functionality and user experience. By seamlessly incorporating the Tomorrow.io Weather API,...
Using AI in Software Development for a Competitive Advantage
In today’s rapidly evolving technological landscape, software development plays a pivotal role in shaping businesses’ success. Companies strive to deliver innovative,...
Docker Secrets Best Practices: Protecting Sensitive Information in Containers
Docker has revolutionized the way we build, ship, and run applications. However, when it comes to handling sensitive information like passwords,...
The Importance of DevOps for SEO Teams and Processes
Check this simple guide to learn how essential DevOps principles and practices can contribute to the efficiency of your SEO teams...
Performing CRUD operations in Mongo using Python and Docker
MongoDB is a popular open-source document-oriented NoSQL database that uses a JSON-like document model with optional schemas. It was first released in...
Efficient Strategies and Best Practices to Minimize Resource Consumption of Containers in Host Systems
Containers have revolutionized the way applications are deployed and managed. However, as the number of containers increases within a host system,...
How to Boost Employee Engagement with Top-rated Software Solutions
Keeping your employees engaged and motivated in today’s fast-paced business world can be challenging. However, employee engagement a crucial in determining...
A First Look at Docker Scout – A Software Supply Chain Security for Developers
With the latest Docker Desktop 4.17 release, the Docker team introduced Docker Scout. Docker Scout is a collection of software supply chain features that...
Getting Started with the Low-Cost RPLIDAR Using NVIDIA Jetson Nano
Conclusion Getting started with low-code RPlidar with Jetson Nano is an exciting journey that can open up a wide range of...

Introduction to Karpenter Provisioner
Karpenter is an open-source provisioning tool for Kubernetes that helps manage the creation and scaling of worker nodes in a cluster....
Update Your Kubernetes App Configuration Dynamically using ConfigMap
ConfigMap is a Kubernetes resource that allows you to store configuration data separately from your application code. It provides a way to...
Mastering the DevOps Mindset: Essential Tips for Students
The demand for skilled professionals in programming, computer science, and software development is soaring in the rapidly evolving world of technology....
How to Choose an IT Career Path that is Right for You
The field of Information Technology (IT) offers a wide array of career opportunities, each with its own unique set of skills...
Shift Left Testing: What It Means and Why It Matters
Shift Left Testing is an approach that involves moving the testing phase earlier in the software development cycle. In traditional models,...
Docker Vs Podman Comparison: Which One to Choose?
Today, every fast-growing business enterprise has to deploy new features of their app rapidly if they really want to survive in...
Kubernetes 101: A One-Day Workshop for Beginners
Are you new to Kubernetes and looking to gain a solid understanding of its core concepts? Join us for a one-day...
Is it a good practice to include go.mod file in your Go application?
Including a go.mod file in your Go application is generally considered a good practice. The go mod command and the go.mod file were...

Think Beyond the Walls of Your Office
A few years ago, a colleague of mine questioned the time and effort I dedicated to organizing Meetups in and outside...
Cybersecurity’s Paradigm Shift: Embracing Zero Trust Security for the Digital Frontier
In a world plagued by persistent cyber threats, traditional security models crumble under the weight of rapidly evolving attack vectors. It’s...Linkerd Service Mesh on Amazon EKS Cluster
Linkerd is a lightweight service mesh that provides essential features for cloud-native applications, such as load balancing, service discovery, and observability....

Exploring the Future of Local Cloud Development: Highlights from the Cloud DevXchange Meetup
The recent Cloud DevXchange meetup, organized by LocalStack in collaboration with KonfHub and Collabnix, brought together developers and cloud enthusiasts in Bengaluru for a day of knowledge-sharing...Automating Configuration Updates in Kubernetes with Reloader
Managing and updating application configurations in a Kubernetes environment can be a complex and time-consuming task. Changes to ConfigMaps and Secrets...
Introducing Karpenter – An Open-Source High-Performance Kubernetes Cluster Autoscaler
Kubernetes has become the de facto standard for managing containerized applications at scale. However, one common challenge is efficiently scaling the...







How to Effectively Monitor and Manage Cron Jobs
Conclusion In conclusion, cron jobs can be a powerful tool for automating repetitive tasks, but they can also create problems if...
DevOps and Digital Citizenship: Teaching Responsible Internet Navigation for Seamless Collaboration
In today’s interconnected world, where the internet has become an integral part of our daily lives, it is essential for students...
Adapting to the AI Revolution: How Writers for Hire Embrace DevOps Challenges
The AI revolution is making waves in virtually every field, including DevOps. The DevOps landscape is becoming more complex with each...
DevOps-Security Collaboration: Key to Effective Cloud Security & Observability
This guest post is authored by Jinal Lad Mehta, working at Middleware AI-powered cloud observability tool. She is known for writing...

Enhancing Collaboration in DevOps: Maximizing Group Work Efficiency With Project Management Software
DevOps is a big trend in IT today. This methodology has been known for a while and is still being actively...
Empowering College Students with Disabilities in DevOps: 5 Essential Resources and Tools
Walking into a classroom or firing up a laptop for an online course can bring a rush of excitement and a...
How to build Wasm container and push it to Docker Hub
WebAssembly (Wasm) has gained significant traction in the technology world, offering a powerful way to run code in web browsers and...
Balancing DevOps Workflows: Choosing Between AI and Expert Writers
DevOps is a set of practices that integrates software development (Dev) and IT operations (Ops), aimed at shortening the systems development...
How to Clear Docker Cache?
Explore how to clean Docker cache to improve performance and optimize disk usage.
Understanding the Mindset of Software Engineers: A Guide for Marketers
I already see you rolling your eyes at this title. Publishing an article on the ‘engineering mindset’ here might seem weird....
Managing Containers with Kubernetes: Best Practices and Tools
Manage containers, and achieve optimal performance, security, and scalability with Kubernetes monitoring. Find essential tools for containerization and observability.
Transforming DevOps Practices: The Impact of Microsoft Surface on Team Productivity
Technological progress has touched all spheres of our lives, especially those connected to information technologies. In the last few years, the...
Is WebAssembly better than JavaScript
The question of whether WebAssembly is better than JavaScript is not straightforward, as both technologies have their strengths and weaknesses. It’s...
Applying DevSecOps Practices to Kubernetes
Special thanks to Mewantha Bandara for contributing this tutorial for the Kubelabs repository. There is an exhaustive list of security measures...
Leveraging Artificial Intelligence in DevOps: 5 Use Cases for Software Development
Artificial Intelligence has the potential to play a crucial role in DevOps and software development. Combined with Machine Learning, it brings...
Kubestalk: Uncovering Hidden Security Risks in Your Kubernetes Clusters
Kubernetes is a popular container orchestration platform used to deploy, scale and manage containerized applications. Kubestalk is a tool that integrates...
Streamlining DevOps Processes: Unveiling the Integration Journey
Like the complex coding assignments that take up countless hours, DevOps is not a process for the faint-hearted. It demands the...
Why You Should Learn Python in 2023?
According to the StackOverFlow 2023 Survey report, Python is the 2nd most admired and desired programming language. What’s driving this significant...
Wasm: Explained to a 5 years old
WebAssembly (abbreviated Wasm) is like a special language that helps computers understand and run programs really fast on the internet. It’s like...





Exploring Cluster Resources with Kubeview: A Visual Approach to Kubernetes Monitoring
Kubeview is a powerful open-source tool that provides a visual representation of your Kubernetes cluster, allowing you to explore resources and...


The Importance of Cybersecurity in Higher Education for DevOps
Cybersecurity is taking new turns on how to function. Read how DevOps enthusiasts should become certified by taking higher education courses.


Wasm and Kubernetes – Working Together
WebAssembly is a binary format that allows running code written in multiple languages (C/C++, Rust, Go, etc.) on the web. This...

How to Become a DevOps Engineer: A Comprehensive Guide
DevOps is more of a methodology than a profession. Since automation pervades the entire workflow, a DevOps specialist needs to have...



The Importance of Mobile Game Analytics: How Data Insights Can Boost Your Gaming Success
Mobile gaming is a booming industry, with millions of players worldwide enjoying games on their smartphones and tablets. As the competition...

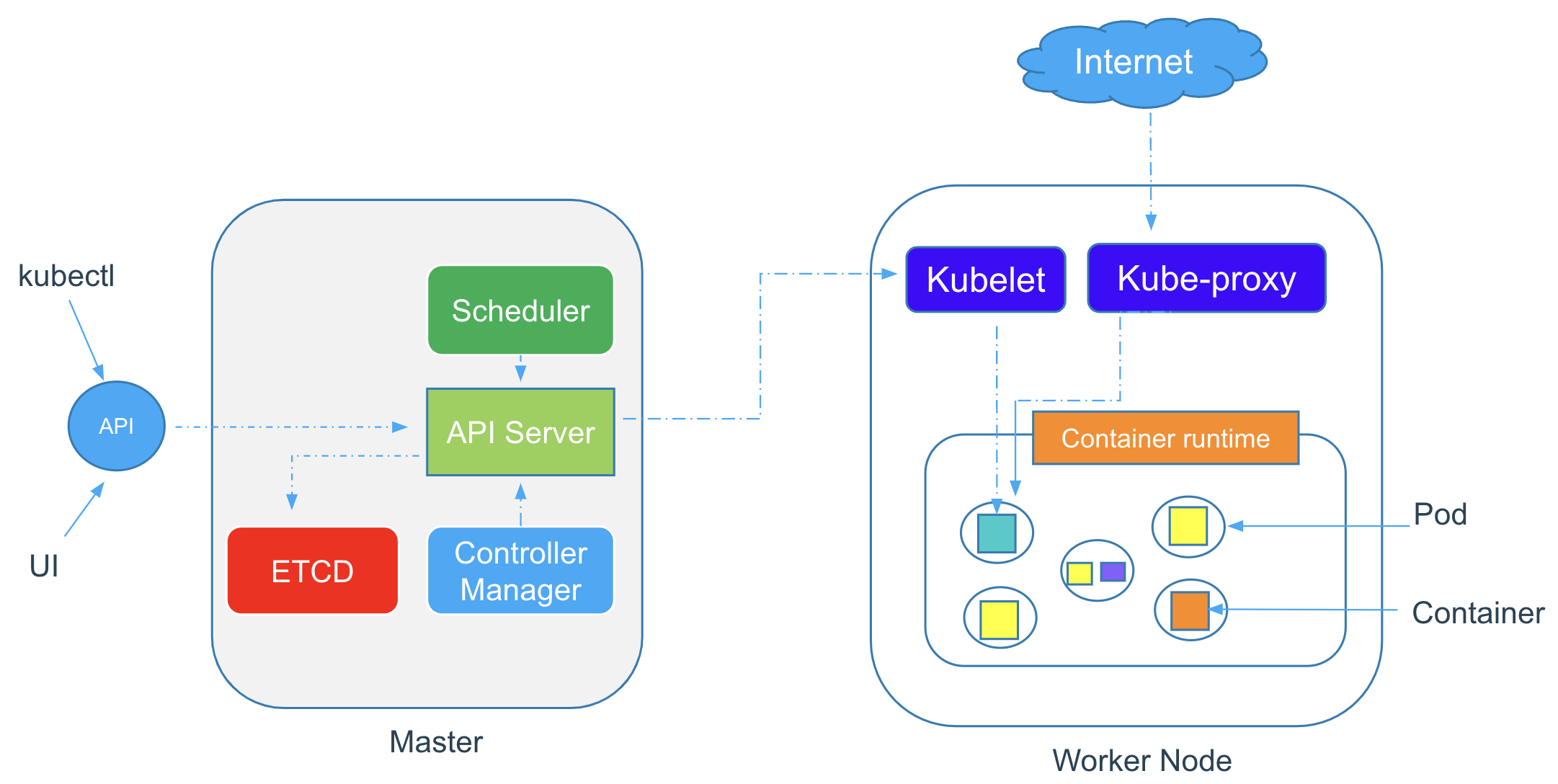
Kubernetes 101 Workshop – A Complete Hands-on Labs and Tutorials
Learn about the fundamentals of Kubernetes architecture in an easy and visual way.
Kubernetes for Python Developers
Kubernetes is a popular container orchestration platform that provides a powerful API for managing containerized applications. The Kubernetes API is a...
15 Kubernetes Best Practices Every Developer Should Know
Explore 15 Kubernetes best practices that every developer should know, along with code snippets and YAML examples
Virtual Reality in Translation Education: Exploring New Dimensions of Language Learning
While the use of virtual reality is far from being innovative, its use in translation education is still relatively new and...
How to fix “An unexpected error was encountered while executing a WSL command” in Docker Desktop
If you’re using Docker Desktop for Windows and you’re seeing the error message "Docker Desktop Unexpected WSL error," it means that...







How to Fix “Support for password authentication was removed” error in GitHub
GitHub is a popular platform for version control and collaboration, but in August 2021, GitHub removed support for password authentication for...
How to reset WordPress Password via PhpMyAdmin
If you have forgotten your WordPress password, you can reset it using PhpMyAdmin. PhpMyAdmin is a web-based application that allows you...
CI/CD vs. DevOps: Understanding 5 Key Differences
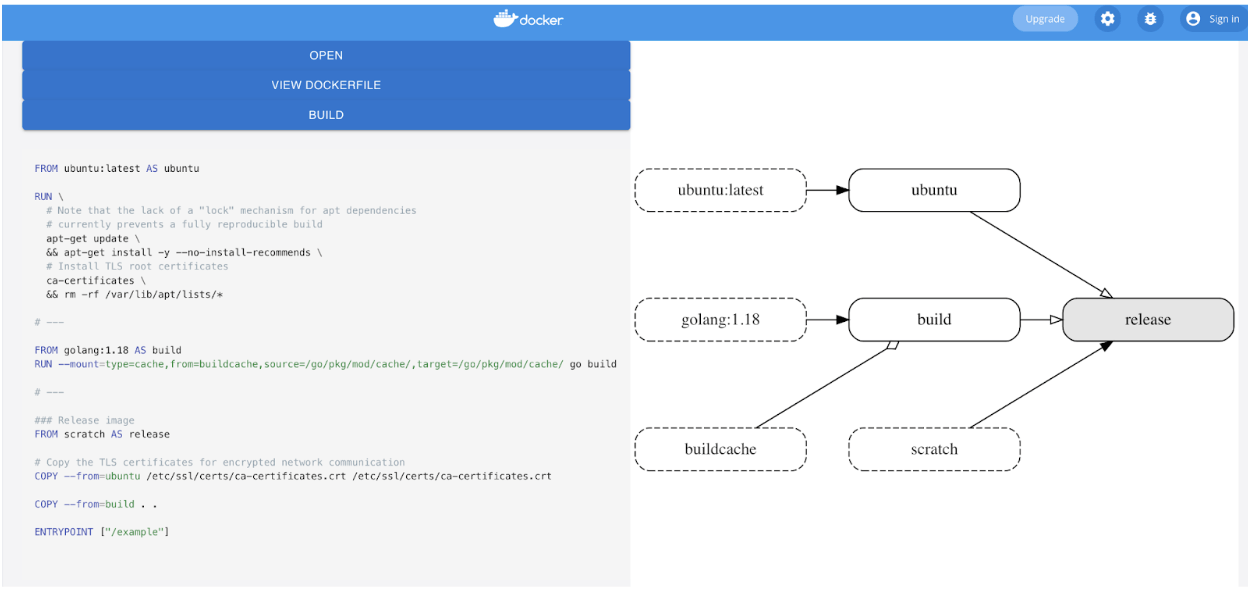
Discover the key differences between CI/CD vs. DevOps, and how these practices work together to revolutionize software development, delivery, and maintenance.Understanding Docker Image Layering Concept with Dockerfile
Docker container is a runnable instance of an image, which is actually made by writing a readable/writable layer on top of...







Error: Docker Failed to Start – Docker Desktop for Windows
Learn how to troubleshoot and fix common issues that cause the "Docker failed to start" error on Windows, such as disabled...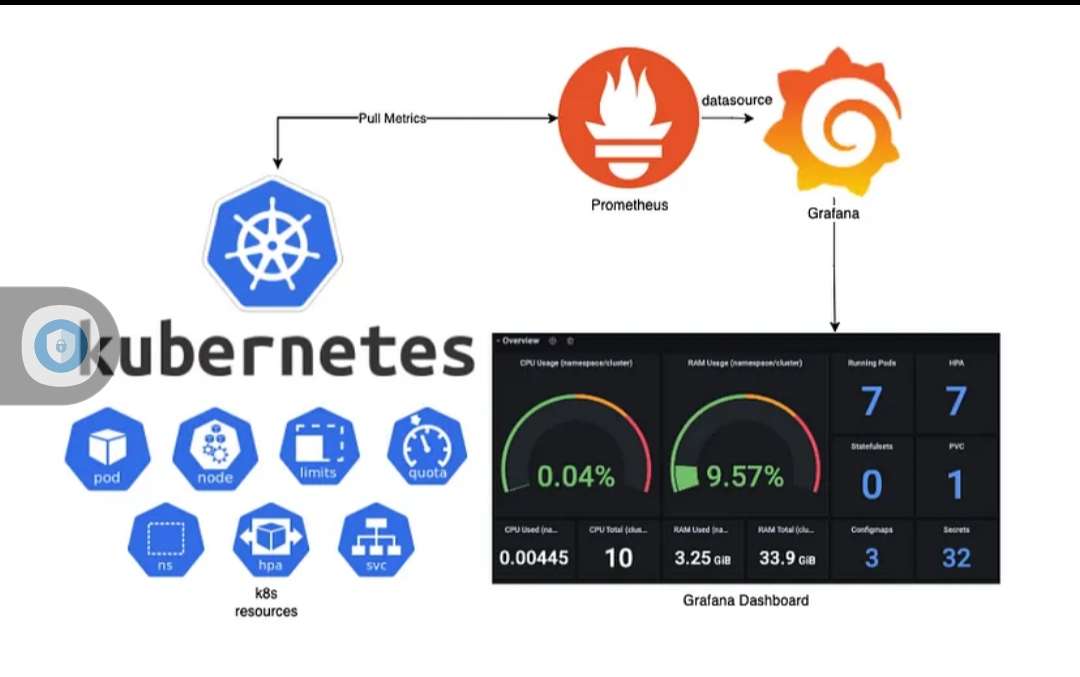










Getting Started with FastAPI and Docker
The architecture of FastAPI is based on the following key components: The architecture of FastAPI is designed to be fast, easy...
Running Arm-based Docker Image on non-Arm Platform using Emulator
QEMU (short for Quick EMUlator) is a free and open-source machine emulator and virtualizer that can run operating systems and programs...
How to Find the Top DevOps Engineers for your Startup
DevOps has become a popular buzzword in the world of technology. It is the collaboration between development and operations to deliver...
Kubernetes Security: 8 Best Practices to Secure Your Cluster
Kubernetes is an open-source platform designed for managing containerized workloads and services. It offers a range of features that make it...
How To Use Traefik v2 as a Reverse Proxy for Docker
Traefik is a powerful and flexible tool for managing traffic and routing requests in modern cloud-native environments. It has become a popular...
Kubernetes ReplicaSet: An Introduction
Kubernetes ReplicaSets are a way of ensuring that a specified number of replicas (i.e., identical copies) of a pod are running...
Navigating the Future of DevOps: The Influence of Emerging Technologies
There is no doubt that new technologies changed our world forever and for the better. Many industries were able to take...
How to Build a Docker Extension From the Scratch
As a developer using Docker Desktop, you have access to a powerful tool that can help you build, share, and run...
Is it Realistic to Open a Business When You are a Student?
There are plenty of cases where students open businesses. Sometimes they will drop out of college because they have a successful...
Is it possible to run Docker container on Arduino Uno?
The short answer is “No, you cannot run Docker containers directly on an Arduino Uno R3 board as it does not...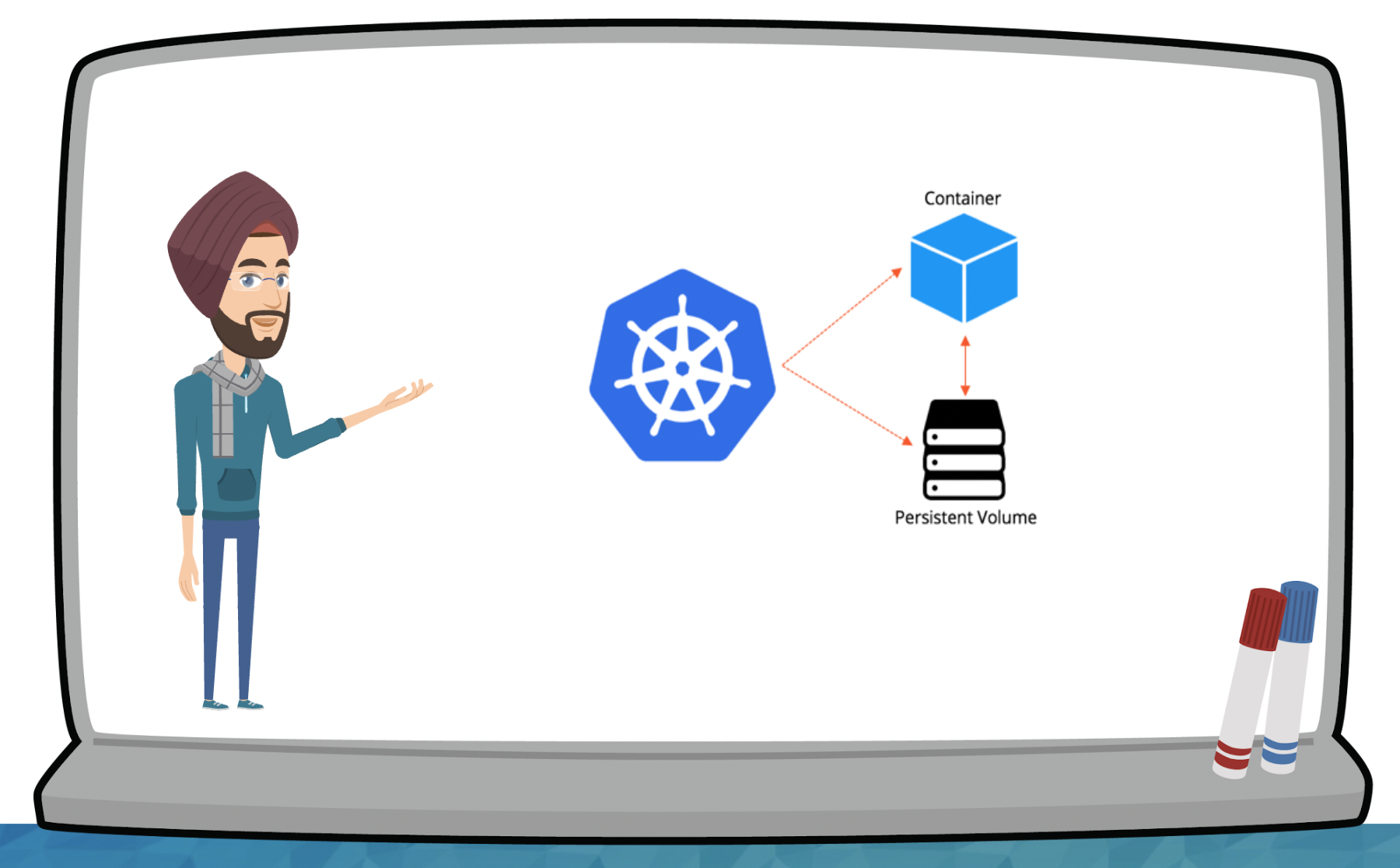
Kubernetes StatefulSets and Its Best Practices
Kubernetes StatefulSets are a type of controller in Kubernetes that manage the deployment and scaling of stateful applications. Stateful applications are...
Implementing CI/CD pipelines for Machine Learning on Kubernetes
Machine learning models have become a critical component of many organizations’ applications and services. To ensure the models are up-to-date, accurate,...
How to Deploy a Simple Wasm and Docker App using Docker Desktop
WebAssembly (Wasm) is a low-level binary format that is designed to be executed in a sandboxed environment, such as web browser....
How to find investors for a college IT startup?
Raising funds for a college startup can be a challenging and competitive process. But with the right approach and resources, it...
Getting Started with Docker and PostgreSQL
PostgreSQL is an open-source relational database management system (RDBMS) that is known for its reliability, robustness, and scalability. It is widely...
Top 10 Security Practices for Enhancing DevOps Security
DevOps is not a new concept, no matter how much it seems to be. The integration of development and operations has...
What is Blockchain Technology and How Does it Work?
Imagine you and your friends have a secret club where you keep your special treasures. To make sure no one takes...
Run And Configure Grafana Docker Image
Grafana provides a comprehensive solution for data visualization, exploration, and monitoring, helping organizations make better decisions by providing them with a...
With Grove Base Hat and OLED I2C Board for NVIDIA Jetson Nano
Grove Shield for Jetson Nano is an expansion board for Jetson Nano, designed by Seeed Studio, for the orderliness of your...
Integrating Slurm with Kubernetes for Scalable Machine Learning Workloads
Machine learning workloads have gained immense popularity in recent years, due to their ability to process and analyze large amounts of...


Top 10 Kubernetes YAML Tips and Tricks
Due to its popularity in the DevOps and container orchestration communities, many organisations and developers who use tools like Kubernetes, Ansible,...
How to Run Microsoft SQL in minutes using Docker Desktop
Docker Desktop for Windows is a Windows-based application that provides a user-friendly interface for developers to build, package, and ship applications...
How to Integrate ChatGPT to a Discord Server and Run as a ChatBot
ChatGPT is a language model developed by OpenAI. It is a variant of the GPT (Generative Pre-trained Transformer) architecture and is...
5 Reasons Why You Should Join Collabnix Community
With over 8000+ Slack members, the Collabnix community has been helping millions of technical engineers worldwide. Collabnix is a community platform for...
How Docker Desktop for Windows works under the Hood?
Docker Desktop for Windows is a version of the Docker platform that is designed to work on Windows operating systems. It...
Can ChatGPT Debug and Fix all of your Docker and Kubernetes Issues?
The short answer is “not 100%”. Here’s the reason why? ChatGPT can provide general information and guidance on Docker issues, but...
Getting Started with Rust and Docker
Rust has consistently been one of the most loved programming languages in the Stack Overflow Developer Survey. Rust tops StackOverflow Survey...
5 Benefits of Docker for the Healthcare Industry
Docker containers have rapidly become a popular technology in the healthcare industry, providing a number of benefits to healthcare providers, researchers,...




How to run Oracle Database in a Docker Container using Docker Compose
Oracle Container Registry (OCR) is a private container registry provided by Oracle Corporation that allows users to store, distribute, and manage container...
Turning ChatGPT into Docker Playground in 5 Minutes
ChatGPT is a highly advanced language model that can perform a wide range of natural language processing tasks with remarkable accuracy....
How to deploy a static site using Mkdocs and Netlify
MkDocs is an open-source static site generator that is used to create documentation websites. It is written in Python and is built...
Getting Started with ChatGPT
What makes Chat GPT a powerful language model? ChatGPT is a powerful language model for several reasons: All of these features...
Running ChatGPT Client locally on Kubernetes Cluster using Docker Desktop
Join our Discord Server Pre-requisite Step 1. Install Docker Desktop Step 2. Enable Kubernetes Step 3. Writing the Dockerfile This Dockerfile...

A Beginner’s Guide to Docker Networking
For Docker containers to communicate with each other and the outside world via the host machine, there has to be a...
Effective Strategies for Integrating AI and ML into Mobile App Development
Discover how to successfully incorporate AI and ML into your mobile app development strategy with these effective tips and techniques. Boost...
Running ChatGPT Client Locally using Docker Desktop
The short answer is “Yes!”. It is possible to run Chat GPT Client locally on your own computer. Here’s a quick...
Using ChatGPT to Build an Optimised Docker Image using Docker Multi-Stage Build
GPT (short for “Generative Pre-trained Transformer”) is a type of language model developed by OpenAI. OpenAI is a nonprofit organisation based...
How to install and Configure NVM on Mac OS
nvm (Node Version Manager) is a tool that allows you to install and manage multiple versions of Node.js on your Mac....

5 Minutes to Memgraph using Docker Extension
Memgraph is a high-performance, distributed in-memory graph database. It is designed to handle large volumes of data and complex queries, making...
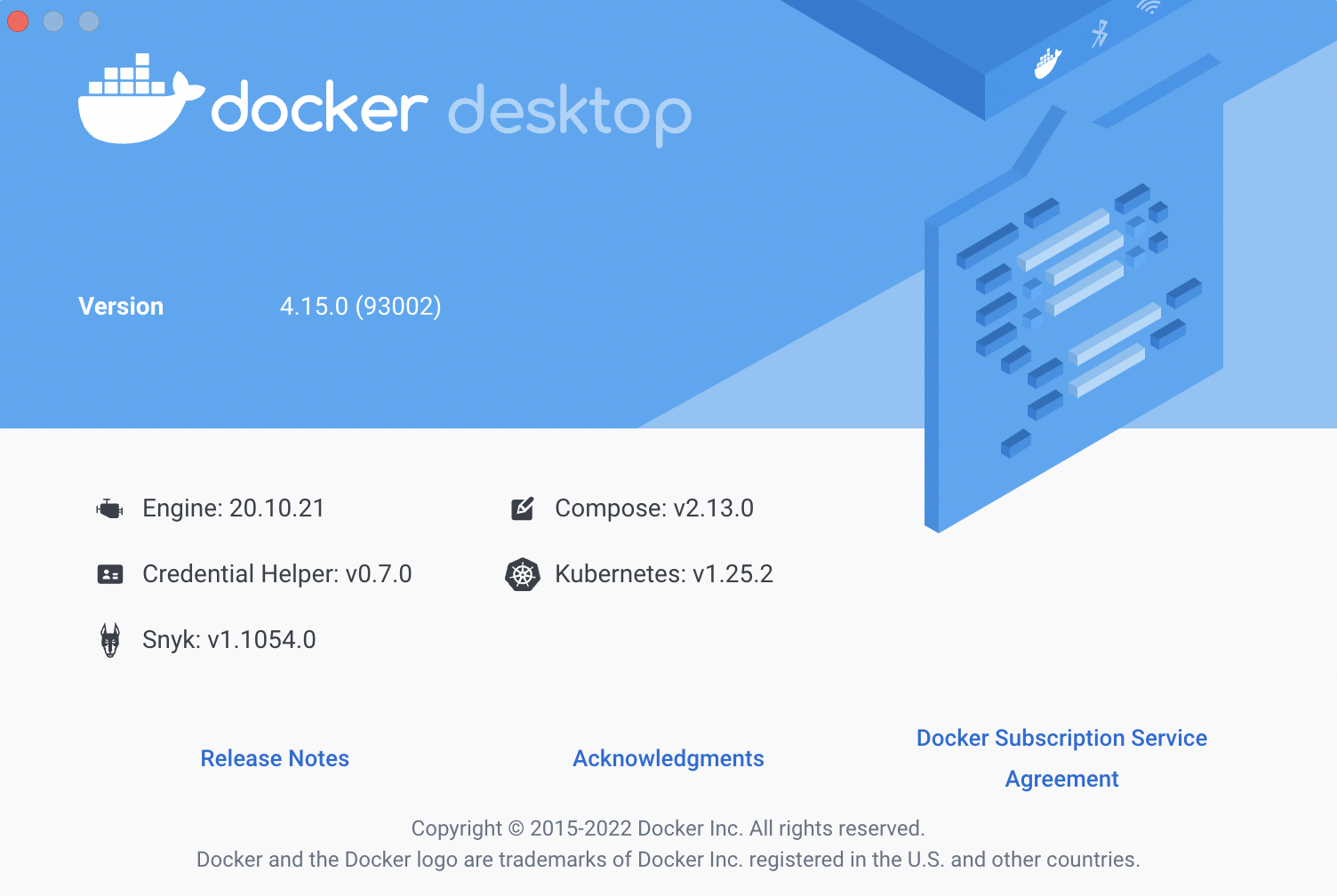
What’s New in Docker Desktop 4.15?
Docker Desktop 4.15 is now available for all platforms – Linux, Windows and macOS. It comes with Docker Compose v2.13.0, Containerd v1.6.10 and Docker Hub...

How to Build & Push Helm Chart to Docker Hub flawlessly
Learn how to build and push Helm Chart to Docker Hub using Docker Desktop
How to Install the latest version of Docker Compose on Alpine Linux(in 2022)
Docker Compose V2 is the latest Compose version that went GA early this year during April 26, 2022. Compose V2 is...
Install and Configure GitLab Runner on Kubernetes using Helm
GitLab Runner is a tool that helps run jobs and send the results back to GitLab. It is often used in...
HubScraper: A Docker Hub Scraper Tool built using Python, Selenium and Docker
Web scraping has become increasingly popular in recent years, as businesses try to stay competitive and relevant in the ever-changing...
Deploy Apache Kafka on Kubernetes running on Docker Desktop
Event-driven architecture is the basis of what most modern applications follow. When an event happens, some other event occurs. In the...
Fluentd – An Open-Source Log Collector
With 11,600 GitHub stars and 1,300 forks, Fluentd is an open-source data collector for unified logging layer. It is a cross-platform...
9 Best Docker and Kubernetes Resources for All Levels
If you’re a developer hunting for Docker and Kubernetes-related resources, then you have finally arrived at the right place. Docker is a...

Getting Started with Docker and Kubernetes on Raspberry Pi
Raspberry Pi OS (previously called Raspbian) is an official operating system for all models of the Raspberry Pi. We will be...