
Model Overview
Nemotron-4-340B-Instruct is a large language model developed by NVIDIA, designed for English-based single and multi-turn chat applications. It has been fine-tuned for improved instruction-following capabilities and mathematical reasoning.
Key points:- Based on the Nemotron-4 architecture
- Supports context length of 4,096 tokens
- Pre-trained on a corpus of 9 trillion tokens
- Fine-tuned using Supervised Fine-tuning (SFT), Direct Preference Optimization (DPO), and Reward-aware Preference Optimization (RPO)
- Optimized for generating high-quality synthetic data
Usage and Deployment
To deploy and use Nemotron-4-340B-Instruct, you can follow these steps:- Create a Python script (call_server.py) to interact with the deployed model
- Create a Bash script (nemo_inference.sh) to start the inference server
- Schedule a Slurm job to distribute the model across nodes
import json
import requests
headers = {"Content-Type": "application/json"}
def text_generation(data, ip='localhost', port=None):
resp = requests.put(f'http://{ip}:{port}/generate', data=json.dumps(data), headers=headers)
return resp.json()
def get_generation(prompt, greedy, add_BOS, token_to_gen, min_tokens, temp, top_p, top_k, repetition, batch=False):
data = {
"sentences": [prompt] if not batch else prompt,
"tokens_to_generate": int(token_to_gen),
"temperature": temp,
"add_BOS": add_BOS,
"top_k": top_k,
"top_p": top_p,
"greedy": greedy,
"all_probs": False,
"repetition_penalty": repetition,
"min_tokens_to_generate": int(min_tokens),
"end_strings": ["<|endoftext|>", "<extra_id_1>", "\x11", "<extra_id_1>User"],
}
sentences = text_generation(data, port=1424)['sentences']
return sentences[0] if not batch else sentences
PROMPT_TEMPLATE = """<extra_id_0>System
<extra_id_1>User
{prompt}
<extra_id_1>Assistant
"""
# Example usage
question = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=question)
print(prompt)
response = get_generation(prompt, greedy=True, add_BOS=False, token_to_gen=1024, min_tokens=1, temp=1.0, top_p=1.0, top_k=0, repetition=1.0, batch=False)
response = response[len(prompt):]
if response.endswith("<extra_id_1>"):
response = response[:-len("<extra_id_1>")]
print(response)
Bash Script for Deployment
Create a Bash script (nemo_inference.sh) to spin up the inference server within the NeMo container:
#!/bin/bash
NEMO_FILE=$1
WEB_PORT=1424
depends_on () {
HOST=$1
PORT=$2
STATUS=$(curl -X PUT http://$HOST:$PORT >/dev/null 2>/dev/null; echo $?)
while [ $STATUS -ne 0 ]
do
echo "waiting for server ($HOST:$PORT) to be up"
sleep 10
STATUS=$(curl -X PUT http://$HOST:$PORT >/dev/null 2>/dev/null; echo $?)
done
echo "server ($HOST:$PORT) is up running"
}
/usr/bin/python3 /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=$NEMO_FILE \
pipeline_model_parallel_split_rank=0 \
server=True tensor_model_parallel_size=8 \
trainer.precision=bf16 pipeline_model_parallel_size=2 \
trainer.devices=8 \
trainer.num_nodes=2 \
web_server=False \
port=${WEB_PORT} &
SERVER_PID=$!
readonly local_rank="${LOCAL_RANK:=${SLURM_LOCALID:=${OMPI_COMM_WORLD_LOCAL_RANK:-}}}"
if [ $SLURM_NODEID -eq 0 ] && [ $local_rank -eq 0 ]; then
depends_on "0.0.0.0" ${WEB_PORT}
echo "start get json"
sleep 5
echo "SLURM_NODEID: $SLURM_NODEID"
echo "local_rank: $local_rank"
/usr/bin/python3 /scripts/call_server.py
echo "clean up dameons: $$"
kill -9 $SERVER_PID
pkill python
fi
wait
Launch nemo_inference.sh with a Slurm script defined like below, which starts a 2-node job for model inference.
Note: The code below uses the <<EOF syntax. When running this code, make sure to use <<EOF exactly as shown to properly define a multi-line string in bash. Replace this part of code which is read -r -d ” cmd EOF to read -r -d ” cmd << EOF
#!/bin/bash
#SBATCH -A SLURM-ACCOUNT
#SBATCH -p SLURM-PARITION
#SBATCH -N 2
#SBATCH -J generation
#SBATCH --ntasks-per-node=8
#SBATCH --gpus-per-node=8
set -x
RESULTS=
OUTFILE="${RESULTS}/slurm-%j-%n.out"
ERRFILE="${RESULTS}/error-%j-%n.out"
MODEL=/Nemotron-4-340B-Instruct
CONTAINER="nvcr.io/nvidia/nemo:24.01.framework"
MOUNTS="--container-mounts=:/scripts,MODEL:/model"
read -r -d '' cmd EOF
bash /scripts/nemo_inference.sh /model
EOF
srun -o $OUTFILE -e $ERRFILE --container-image="$CONTAINER" $MOUNTS bash -c "${cmd}"
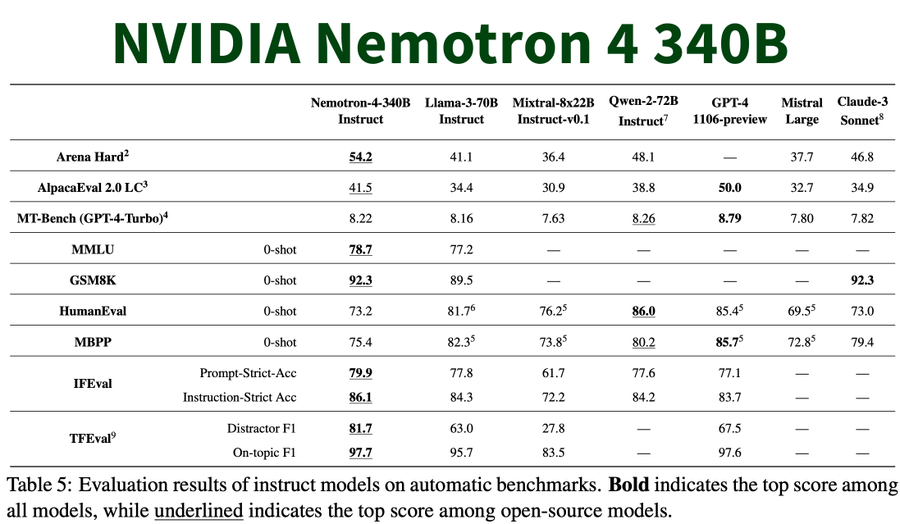
Evaluation Results
The model has been evaluated on several benchmarks:- MT-Bench (GPT-4-Turbo): 8.22 overall score
- IFEval: 79.9% Prompt-Strict Accuracy, 86.1% Instruction-Strict Accuracy
- MMLU: 78.7%
- GSM8K: 92.3%
- HumanEval: 73.2%
- MBPP: 75.4%
- Arena Hard: 54.2%
- AlpacaEval 2.0 LC: 41.5%
Safety Evaluation
The model underwent safety evaluation using three methods:- Garak: Automated LLM vulnerability scanner
- AEGIS: Content safety evaluation dataset and classifier
- Human Content Red Teaming
Limitations and Ethical Considerations
This model has been trained on datasets that may include toxic language, unsafe content, and societal biases sourced from the internet. As a result, it might inadvertently amplify these biases and produce toxic outputs, especially when faced with prompts that contain harmful language. There is a possibility that the model could generate responses that are inaccurate, lack essential information, or include irrelevant or repetitive text, leading to socially unacceptable or undesirable results, even if the initial prompt does not contain explicit offensive language.
NVIDIA views the creation of Trustworthy AI as a collective responsibility and has implemented policies and practices to support the development of various AI applications. When utilizing this model in line with our terms of service, developers should collaborate with their internal model teams to ensure it aligns with industry standards and specific use cases, addressing any potential misuse. For comprehensive insights into the ethical considerations related to this model, including aspects of explainability, bias, safety, security, and privacy, please refer to the Model Card++ resources. Additionally, any security vulnerabilities or concerns regarding NVIDIA AI can be reported here.

Try this project with
- Setup your local or cloud development environment in minutes:
- Step 1 of 2:
- Try this project with
- NVIDIA AI Workbench
- Step 2 of 2:
- Copy the URL below:
https://github.com/NVIDIA/workbench-example-hybrid-rag- Open AI Workbench
- Clone the project in AI Workbench using the link above.
- Install NVIDIA AI Workbench using the button below.
- Or click “I Already Have AI Workbench.”
- Get Function Deployment Details
- API Request:
GET https://api.nvcf.nvidia.com/v2/nvcf/deployments/functions/{functionId}/versions/{functionVersionId}
- Allows Account Admins to retrieve the deployment details of the specified function version. Access to this endpoint mandates a bearer token with ‘deploy_function’ scope in the HTTP Authorization header.
- Log in to see full request history:
- Time | Status | User Agent
- — | — | —
- Make a request to see history.
- Path Params:
functionId- string (required)
- Function id
functionVersionId- string (required)
- Function version id
- Response:
- Language:

- Request:
import requests
url = "https://api.nvcf.nvidia.com/v2/nvcf/deployments/functions/functionId/versions/functionVersionId"
headers = {"accept": "application/json"}
response = requests.get(url, headers=headers)
print(response.text)
