
Welcome to the world of Large Language Models (LLMs), where the intricate dance of algorithms brings language to life! If you’ve interacted with digital assistants, used predictive text, or marvelled at how a computer can summarize lengthy articles, you’ve seen LLMs in action. These technological marvels are not just transforming how we interact with machines but are also reshaping the frontiers of human knowledge and creativity.
What is a Large Language Model?
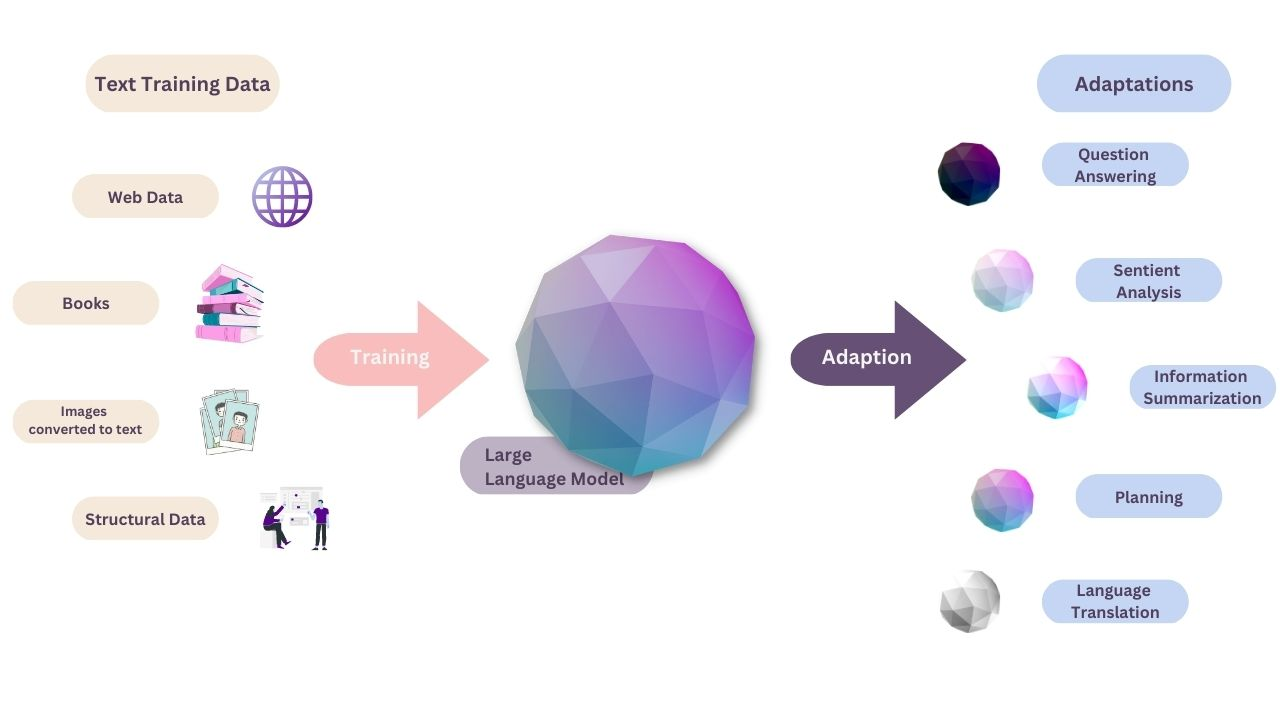
A Large Language Model (LLM) is a type of artificial intelligence that understands and generates human-like text by predicting the likelihood of a sequence of words. It’s like having a virtual linguist inside your computer—one that has read a vast library of books, articles, and websites to learn the nuances of human language.
These models are “large” not just in their physical size, requiring substantial computational power, but in the scope of their learning and capabilities. They are trained on diverse internet text, learning patterns, structures, and the idiosyncrasies of language from countless genres and styles. This extensive training enables them to perform a variety of language-based tasks such as translating languages, answering questions, composing poems, generating readable text on demand, and even coding!
How Do LLMs Work?
At their core, LLMs leverage an architecture known as the Transformer, which relies heavily on a mechanism called “attention.” This allows the model to focus on relevant parts of the text as it reads, mimicking how a human might pay more attention to keywords or phrases while skimming a document. The Transformer processes words simultaneously, making it significantly faster and more scalable than its predecessors.
Large Language Models (LLMs) work by leveraging vast amounts of text data to learn the statistical properties of language and generate coherent and contextually relevant text. Here’s a simplified explanation of how they work:
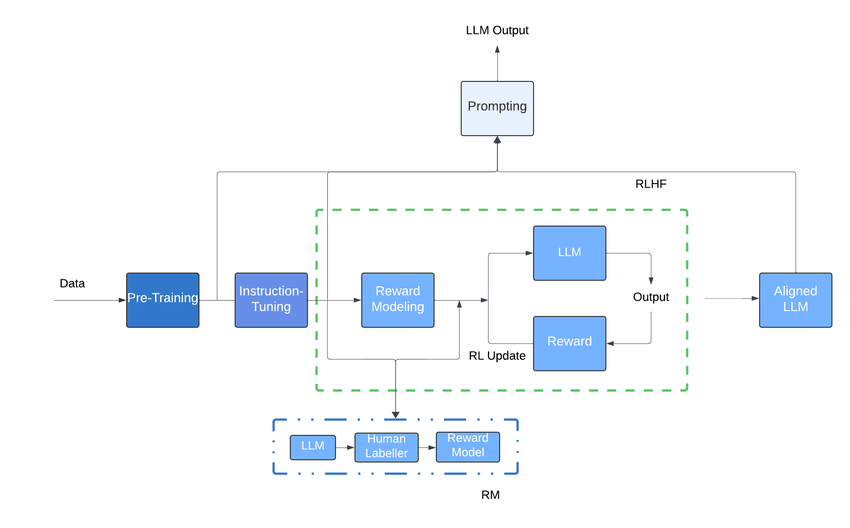
1. Pre-training: LLMs start by pre-training on large corpora of text data, such as books, articles, and websites. During pre-training, the model learns to predict the next word in a sequence of words given the preceding context. This process is often implemented using a transformer architecture, which is highly effective for capturing long-range dependencies in text.
LLMs undergo two major phases: pre-training and fine-tuning.
2. Fine-tuning: After pre-training, the model is fine-tuned on a smaller, task-specific dataset. This step adjusts the model’s weights slightly to specialize in tasks like sentiment analysis, summarization, question answering, etc.Fine-tuning involves further training the model on a smaller, task-specific dataset to adapt it to the particular task’s requirements. This step helps the model specialize in tasks like text classification, language translation, or text generation.
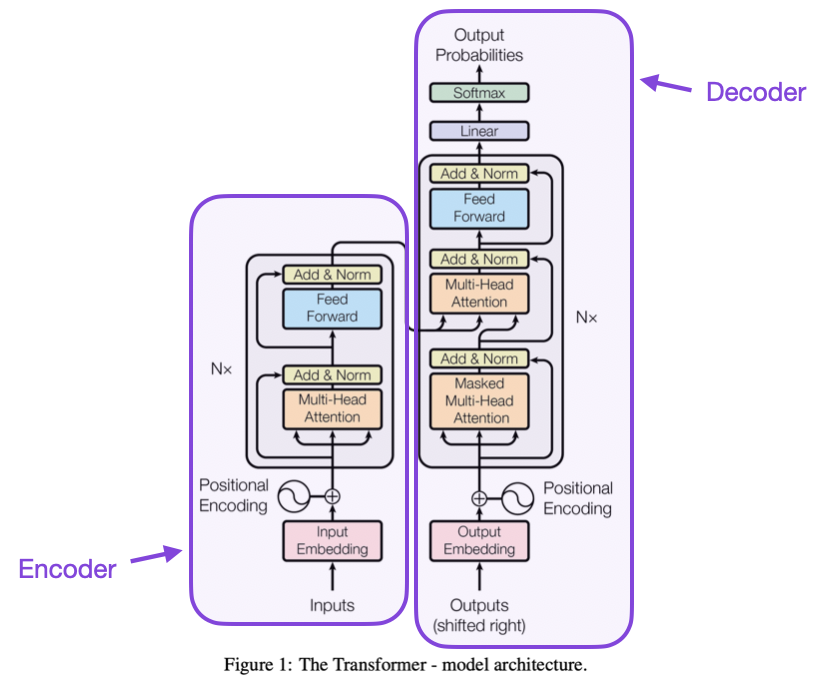
2. Transformer Architecture: LLMs are typically built upon transformer architectures, which consist of several layers of self-attention mechanisms and feedforward neural networks. Self-attention allows the model to weigh the importance of each word in the context when generating the next word. This attention mechanism enables the model to capture relationships between words that are crucial for understanding context and meaning.
Large language models (LLMs) like OpenAI’s GPT (Generative Pre-trained Transformer) series have become a significant area of interest in artificial intelligence and natural language processing. These models have demonstrated remarkable abilities in generating human-like text, understanding context, answering questions, translating languages, and more. To understand these models comprehensively, we can explore their architecture, training processes, applications, challenges, and ethical considerations.
Large language models are based on the transformer architecture, introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017. The transformer model is distinct from its predecessors due to its reliance on attention mechanisms, particularly self-attention, which allow the model to weigh the importance of different words in a sentence, irrespective of their distance from each other in the text.
These models typically consist of layers of transformer blocks that include:
- Self-attention layers: Help the model understand the context of each word in a sentence by relating different words to one another.
- Feed-forward neural networks: Apply further transformations to the data processed by the attention layers.
- Normalization and residual connections: Help in stabilizing the learning process and allow gradients to flow through the network effectively during training.

3. Inference: Once trained or fine-tuned, the LLM can be deployed for inference. During inference, the model takes input text and generates output text based on its learned knowledge and understanding of language. The generated text can be in the form of responses to prompts, translations of text into different languages, or summaries of longer passages, depending on the task for which the model was trained.Industry Giant NVIDIA launched four inference platforms optimized for a diverse set of rapidly emerging generative AI applications — helping developers quickly build specialized, AI-powered applications that can deliver new services and insights. In Addition,
EmbeddedLLM has chosen to exclusively utilize AMD for inference due to the company’s promising advancements in hardware architecture and open software ecosystems. By leveraging AMD’s CDNA3 GPU blocks and Zen 4 CPU blocks, coupled with high-bandwidth memory (HBM), EmbeddedLLM aims to deploy LLMs across various devices, including edge devices and laptops, with low power requirements. The decision to rely on AMD is rooted in their proven track record of executing roadmap strategies, exemplified by the success of the Zen architecture. Additionally, the accessibility of open software ecosystems, such as ROCm, further enhances the compatibility and flexibility of deploying LLMs on AMD-powered devices.
4. Evaluation: LLMs are evaluated based on their performance on specific tasks, such as language understanding, text generation quality, or task completion accuracy. Evaluation metrics may vary depending on the task but often include measures like perplexity (a measure of how well the model predicts text) or BLEU score (a measure of translation quality).
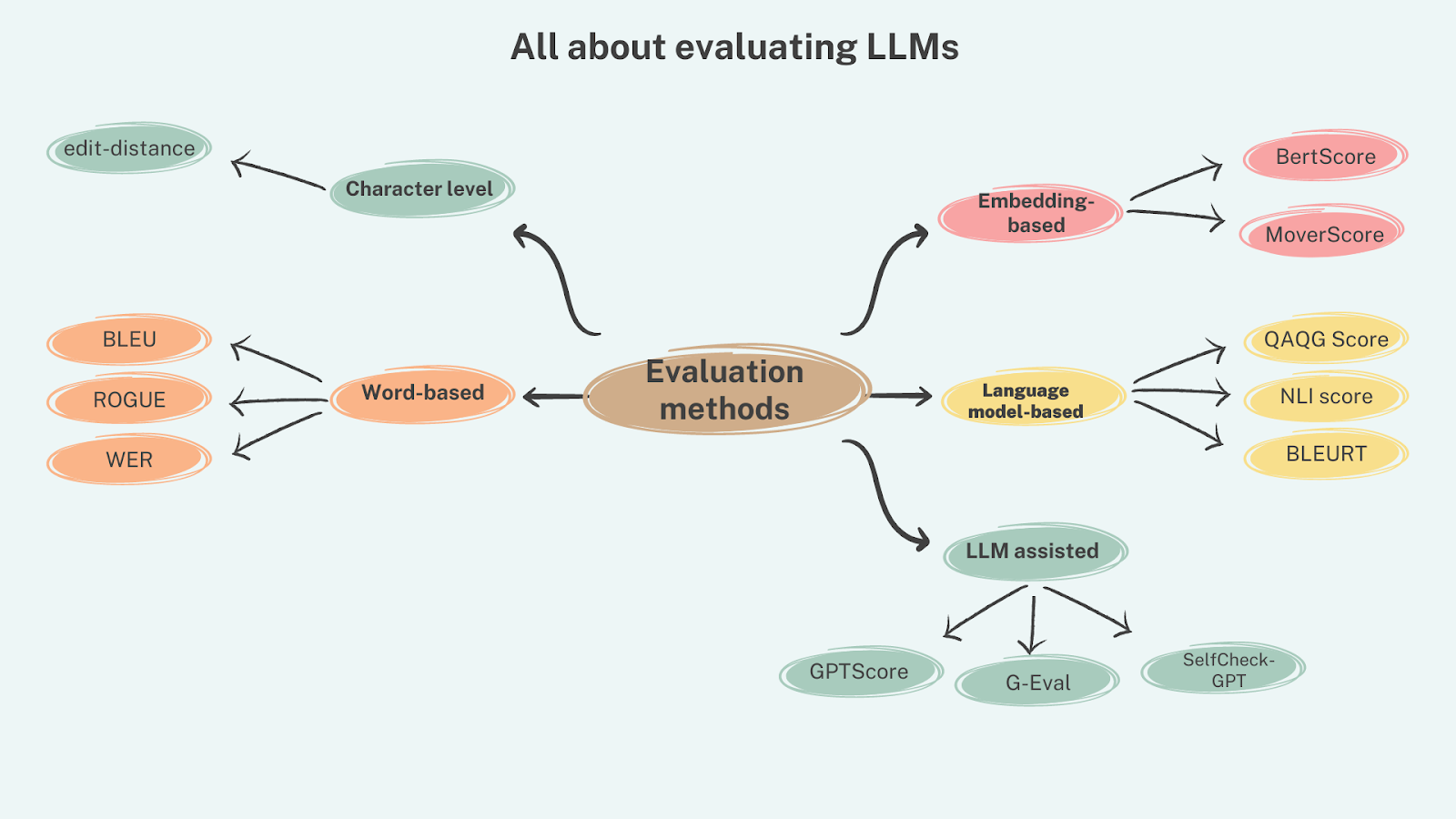
Evaluating the proficiency and limitations of Large Language Models (LLMs) is a crucial step in understanding their capabilities in comprehending, generating, and interacting with human language across various tasks. This evaluation process typically falls into two broad categories: Natural Language Understanding (NLU) and Natural Language Generation (NLG). Let’s delve into each category and explore some notable evaluation benchmarks:
Natural Language Understanding (NLU)
NLU tasks gauge the language comprehension abilities of LLMs across a spectrum of tasks, including:
– Sentiment analysis
– Text classification
– Natural Language Inference (NLI)
– Question Answering (QA)
– Commonsense Reasoning (CR)
– Mathematical Reasoning (MR)
– Reading Comprehension (RC)
Natural Language Generation (NLG)
NLG tasks focus on assessing the language generation capabilities of LLMs, often by understanding the provided input context. These tasks include:
– Summarization
– Sentence completion
– Machine Translation (MT)
– Dialogue generation
Prominent Evaluation Datasets
Several datasets have been proposed for evaluating LLMs across different tasks. Here are a few famous datasets within each category:
– NLU Datasets:
– SQuAD (Stanford Question Answering Dataset)
– CoNLL (Conference on Natural Language Learning)
– GLUE (General Language Understanding Evaluation)
– NLG Datasets:
– CNN/Daily Mail (News Article Summarization)
– WMT (Workshop on Machine Translation)
– Persona-Chat (Persona-Based Dialogue Generation)
Multi-task Evaluation Benchmarks
In addition to individual task datasets, multi-task benchmarks provide a comprehensive evaluation of LLMs across diverse tasks. Here are some notable examples:
– MMLU (Multi-Modal Language Understanding): This benchmark measures the knowledge acquired by models during pretraining and evaluates them in zero-shot and few-shot settings across various subjects, testing both world knowledge and problem-solving ability.
– SuperGLUE (Super General Language Understanding Evaluation): A successor to the GLUE benchmark, SuperGLUE offers a more challenging and diverse set of language understanding tasks, including question answering, natural language inference, and co-reference resolution. It aims to provide a rigorous test of language understanding capabilities.
– BIG-bench (Behavior of Intelligent Generative Models Benchmark): Designed to test LLMs across a wide range of tasks, BIG-bench evaluates their abilities in reasoning, creativity, ethics, and understanding of specific domains on a large-scale benchmark.
In summary, evaluating LLMs involves assessing their performance across various NLU and NLG tasks, utilizing both individual task datasets and comprehensive multi-task benchmarks. These evaluations help researchers and practitioners understand the strengths and weaknesses of LLMs and drive advancements in natural language processing technology.
In our next blog, you will learn about LLM and why they are super important.