







Docker More

Calling All Bengaluru Developers: Join Me at Arm DevHub Live & Master Docker Build Cloud!
Excited to present at Arm DevHub Live: Bangalore on May 3rd! Join for workshops, demos, and networking opportunities in...
Error: Docker pull Intermittent TLS handshake timeout
The docker pull is one of the basic commands in Docker, and it is used to fetch image files...
“sh: next: command not found” in Next.js Development? Here’s the Fix!
Struggling with the "sh: next: command not found" error in your Next.js project? Learn how to fix it by...
Introduction to Generative AI
Imagine a tool that can create entirely new and original content, from captivating poems to never-before-seen images. That’s the...
The Future Is Here: How Intelligent Process Automation Is Changing Industries
Discover how intelligent process automation services are revolutionizing the workplace, boosting efficiency, and enhancing customer experiences. Read on to...
Crafting Brilliance: 5 Strategies For Aspiring Product Designers
Starting as a designer can be tough, but with the right strategies, you can succeed. From continuous learning to...Begin Your Java Journey with BlueJ: A Beginner-Friendly Tool for Coding Success
Learn Java with BlueJ, a beginner-friendly tool! Dive into Java programming with a simple interface, visual objects, and interactive...How AI Integration in IoT Transforms Inventory Management
Discover how integrating AI with IoT is revolutionizing inventory management, leading to enhanced efficiency, cost savings, and a competitive...All Stories

Best Practices For Securing Containerized Applications
Discover the best practices for securing containerized applications in this guide. Learn how to protect your digital assets from threats and...
Best Possible Ways to Recreate Content
Struggling to recreate content? This guide will help you revitalize your old content with ease. Learn how to add new info,...
Why Should You Build a Special Document Management System?
Discover the advantages of developing a custom document management system, from maximizing efficiency to improving teamwork and protecting sensitive information.
How is GenAI different from ChatGPT?
Discover the differences between GenAI and ChatGPT in the world of generative AI! Learn how these technologies excel in various applications...
How MLOps Consulting Drives Enterprise Efficiency
Discover how MLOps is revolutionizing enterprise ML operations, improving efficiency through automation, consistency, monitoring, and collaboration.
Why Every Business Needs Remote DBA Support for Effective Data Management
In the modern business landscape, effective data management is essential for success. Remote DBA support offers high availability and expertise for...
Navigating the Digital Highway: A Comprehensive VPN Selection Guide for Businesses
In a world rife with cyber threats, choosing the right VPN for your business is crucial. Join us as we unravel...Maximize Efficiency: The Benefits of Hiring a Microsoft Dynamics Consultant
Discover the benefits of hiring a Microsoft Dynamics consultant for your business, from customization to performance optimization and ongoing support.
How AI and VPN Technology Enhance Each Other
Discover the symbiotic relationship between AI and VPN technologies in enhancing privacy, security, and accessibility in the digital world. #AI #VPN...
How to uninstall Ollama
Looking to uninstall Ollama from your system? Follow these simple steps to bid it farewell and clean up your system smoothly....
What is Data Backup? Why Backups Matter and How to Do Them Right?
Discover the importance of data backup, why it's crucial, and how to keep your digital life safe. Learn about data loss...
Building a Sentiment Analysis Tool Using Python: A Step-by-Step Guide
Discover the power of sentiment analysis using Python! Learn how to decode emotions in text data with NLTK and TextBlob libraries...
What is DevRel and Why It Matters in the Tech World
So, you’ve heard the term “DevRel” thrown around, and you’re not quite sure what all the buzz is about, right? Don’t...
Top 5 Community Tools Every DevRel Should Have for Building a Thriving Developer Community
Discover the top 5 community tools every DevRel needs! From community management platforms to content creation tools, this guide has you...
Is Kubernetes ready for AI
Unleash the power of AI with Kubernetes! Explore its compatibility, advantages, and potential as the ultimate solution for AI workloads in...
How to Download and Install Kubernetes
Kubernetes has become the de facto standard for container orchestration, providing a scalable and resilient platform for managing containerized applications. In...
Data Backup in Kubernetes
According to a study by Gartner analysts, by 2025, 95% of new digital workloads will be deployed on cloud-native platforms, up...
Why does AI need GPU?
Artificial intelligence and machine learning are amazing technologies that can do incredible things like understand human speech, recognize faces in photos,...
Dagger: Develop your CI/CD pipelines as code
Our traditional CI/CD tools are usually rigid and have predefined workflows that make customization limited. They require an extensive amount of...
Smart Money in Smart Technology: Investing in Large IoT Projects
Explore the world of large IoT projects, their benefits, risks, and key considerations for investors. Learn how to invest strategically at...
AI and Machine Learning: The New Frontier for Investors
Discover how AI and machine learning are transforming the world of finance, reshaping investment strategies and unlocking new potentials for investors.
Cloud-Native Technology: A Guide for Investors to Navigate the Cloud Computing Boom
Discover the potential of cloud-native ventures and navigate the volatile landscape of cloud computing investments with our comprehensive guide. Gain insights...
Integrating Power BI Consulting Services into DevOps Practices
Microsoft’s Power BI is a business analytics tool that provides interactive visualizations and business intelligence capabilities with an interface that is...
Data Breaches: Why Employee Training is Your Best Defence
Learn why employee training is crucial in preventing data breaches. Discover the different types of breaches and how proper training can...
Monitoring Containerd
Learn the importance of monitoring Containerd, its architecture, and tools for tracking performance, resource utilization, and health for efficient container operations....
Kubernetes for Java Developers
If you consider the Kubernetes architecture, you will see that there is a Kubernetes API which is called to perform operations...
How to Run Docker in a Rootless Mode
Learn how to set up Docker in Rootless mode on Ubuntu or Debian systems to reduce security risks and run containers...
Ukrainian Developers’ Reality in 2024
The IT sector in Ukraine has always been and continues to be one of the most prominent and talent-rich in Europe....
Your Guide to the Top 6 Mobile Games
Explore the top 10 mobile games that are taking the gaming world by storm. From addictive puzzles to action-packed adventures, find...
How to setup Ollama with Ollama-WebUI using Docker Compose
Unlock the potential of Ollama, an open-source LLM, for text generation, code completion, translation, and more. See how Ollama works and...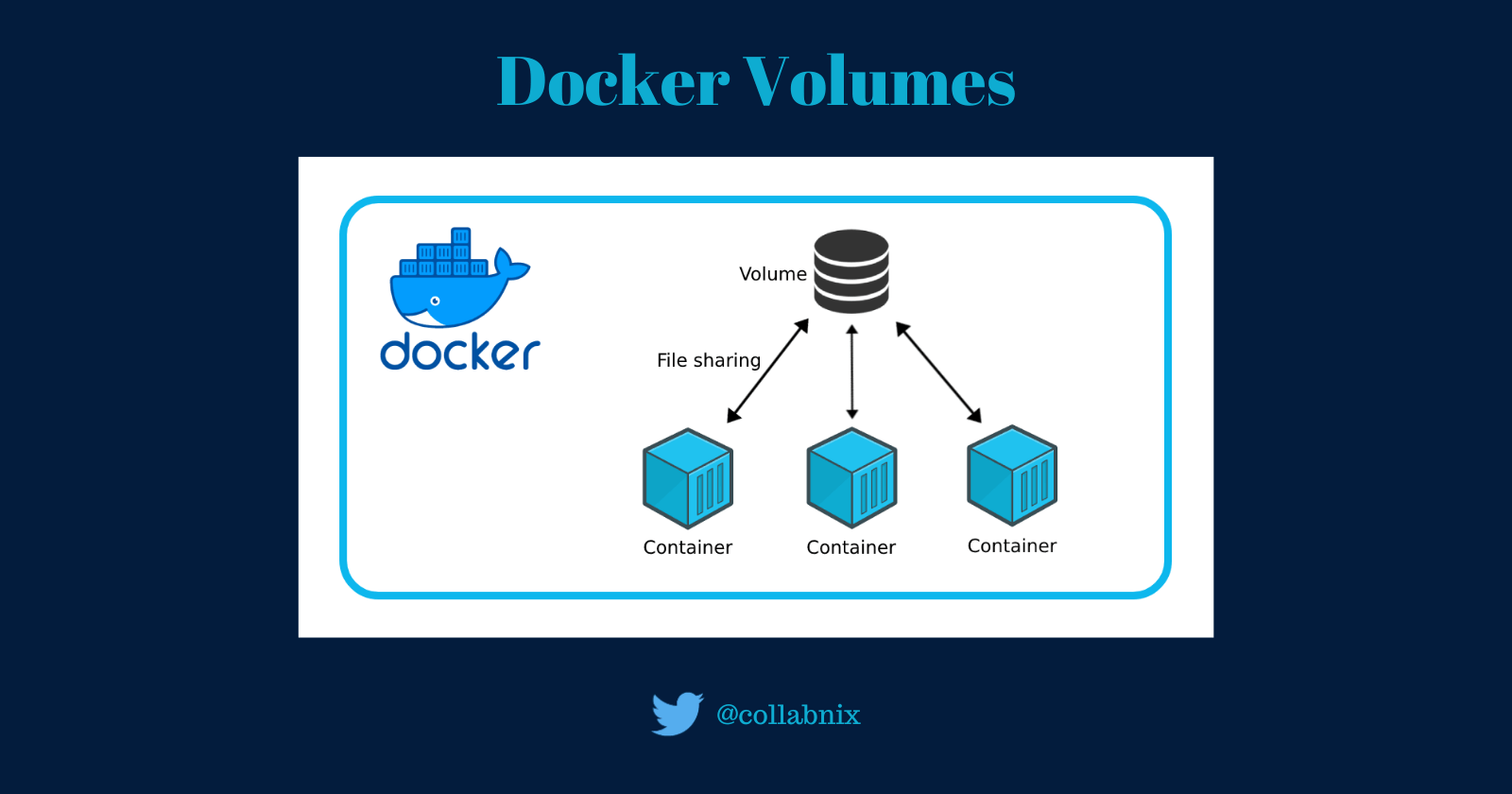
Docker Volumes- A Complete Guide with Examples
Docker volumes is an extensive feature of Docker that allows data to be stored and managed persistently. The volumes allow data...
How to Run Ollama with Docker Desktop and Kubernetes: A Step-by-Step Guide
Discover how to effectively leverage the potential of Ollama within your development workflow using Docker Desktop and Kubernetes for seamless containerization...
Tips on Finding the Best PDF Editor for Your Company
Looking for the best PDF editor for your business? Here are some tips on finding one that offers automation, cross-platform use,...
Using Docker GenAI Stack with GPU for Generative AI Models
Introducing the Docker GenAI Stack, a set of open-source tools that simplify the development and deployment of Generative AI applications. With...
How to Easily Transition from.NET Framework to.NET Core
Upgrading enterprise-scale .NET Framework applications to .NET Core for cloud capabilities needs careful planning. Follow these steps for a smooth transition.
How To Build a Node.js Application with Docker in 5 Minutes
Learn how to quickly containerize your Node.js app using Docker. Follow this guide for an efficient way to get started with...
Running Docker Containers as Root
Running containers with root privileges – a contentious topic in the Docker community. By default, Docker containers run with limited privileges...
What’s New in Kubernetes 1.30 Release?
Heads up, Kubernetes users! Version 1.30 is almost here, packing a punch for both security defenders and developers. Here’s a breakdown...
Mastering Fortnite: Tips for Improving Your Skills
Fortnite has become a global phenomenon, captivating millions of players with its dynamic gameplay and constant updates. Whether you’re a casual...
Kubernetes and AI: 3 Open Source Tools Powered by OpenAI
As per the recent Cloud-Native AI report generated by CNCF during the KubeCon + CloudNativeCon Europe conference, AI is empowering operators and developers...
MAUI vs Flutter for Cross-Platform Development in 2024
In the rapidly evolving world of software development, the quest for the most efficient, versatile, and robust framework for cross-platform application...Kubernetes for Python Developers
Kubernetes is a popular container orchestration platform that provides a powerful API for managing containerized applications. The Kubernetes API is a...
Collabnix Monthly Newsletter – March 2024
Welcome to the Collabnix Monthly Newsletter. We bring you a list of the latest community-curated tutorials, sample apps, events, and videos....
The Impact of IoT on Oil Investment Opportunities and Risks
The Internet of Things (IoT) is revolutionizing the oil industry, offering new opportunities and challenges for investors. This article explores the...
AI-Powered Investing: Enhancing Decision-Making and Returns
Artificial Intelligence (AI) is transforming the landscape of investing, offering powerful tools to enhance decision-making and improve returns. AI-powered algorithms can...
Demystifying WebAssembly: A Guide for Beginners
Despite its name, WebAssembly (a.k.a Wasm) is not quite an assembly language. It’s not meant for any particular machine. It’s for...
What is WebAssembly and how it is different from JavaScript
So, you’ve probably heard of WebAssembly, right? It’s this cool, low-level binary thing that’s shaking up the web development scene. Instead...
Understanding Cloud Operating Models
Cloud computing has recently become an essential tool for businesses of all sizes. However, simply migrating to the cloud isn’t enough....
Dive Into the Future of Docker Development at Docker DevTools Day Bengaluru!
Calling all tech and Docker enthusiasts! Don't miss the first-ever Docker DevTools Day in Bengaluru, a celebration of innovation, collaboration, and...
Azure DevOps Path: Understanding the Definition and Best Practices
Embark on a human-friendly exploration of the Azure DevOps Path. Demystify the platform, learn best practices, and navigate your software delivery...
Optimizing Operations: Effective Kubernetes Best Practices for Platform Teams
As the cloud-native ecosystem expands, organizations often find themselves at a crossroads when beginning their Kubernetes journey, unsure of which path...
Docker Compose vs. Kubernetes: A Comparative Analysis with a Sample Application Example
Discover the differences between Docker Compose and Kubernetes in managing containerized apps. Learn when to use each tool for your projects....
What is ChatGPT and why it is damn popular?
In the rapidly evolving landscape of artificial intelligence (AI), one of the most fascinating developments is ChatGPT, a chatbot designed by...
How is MVP Solutions Used in Service Development
In the realm of service development, MVP (Minimum Viable Product) solutions have emerged as a strategic approach to validate ideas and...
How IoT Integration is Revolutionizing IT Asset Management Software
Discover the impact of IoT integration in asset management, from improved efficiency to proactive maintenance. Learn how IoT devices revolutionize IT...
Security Health Checks for Applications: Safeguarding Against Cyber Threats
In a world of increasing cyber threats, secure applications are a necessity. Learn why Security Health Checks and APM are crucial...
Latest Cutting-Edge Trends Defining Fintech Trading
Discover the top tools and keep up with innovative changes, development, and deployment of fintech tools that enhance financial trading experiences.
Docker Build Cache Explained
One of the key features of Docker is the ability to build images from a set of instructions in a Dockerfile....
SonarQube Integration with Docker Scout: Ensuring Code Quality for Docker Images
SonarQube is a powerful tool for continuous code quality inspection, helping developers enhance code quality by identifying bugs, code smells, security...
Why Ollama is Crucial for Docker GenAI Stack?
Discover how Ollama server enables Mac users to efficiently run Docker GenAI stacks with large language models, offering speed, privacy, and...
Tools Developers Use When Building Websites That Stand Out And Make A Splash
Discover what tools and techniques developers use to create amazing websites, from Python for functionality to security tech and JavaScript for...
The Role of AI in Custom Software Development
Discover how Artificial Intelligence is transforming the world of custom software development. Learn how AI is enhancing operational efficiency and addressing...
Secure Coding Essentials for SAP Business Systems
If you are a developer, understanding the needs of your SAP system is key. Here are some best-practice tips.
How To Fix “ImagePullBackOff” Error in Kubernetes
Learn how to troubleshoot the "ImagePullBackOff" error in Kubernetes pods due to various reasons like incorrect image names, tags, network issues,...
Top 5 CI/CD Tools for Kubernetes
Explore the top 5 CI/CD tools for Kubernetes in this article, with tips for choosing the right tool and best practices...
Comparison of CKA vs CKAD: Which Kubernetes Certification is Right for You?
Discover the differences between the CKA & CKAD Kubernetes certifications. Learn about exam formats, prerequisites, and benefits for your career growth.
CKA vs CKAD vs CKS – What is the Difference
Looking to enhance your Kubernetes skills with certification? Learn about CKA, CKAD, and CKS certifications, their specifics, and how to prepare...
How to Fix ‘Terminated With Exit Code 1’ Error in Kubernetes
Learn how to troubleshoot the Exit Code 1 error in Kubernetes containers. Discover causes and solutions to resolve this frustrating issue...
Effective Tips to Help Make Remote Learning More
Learn how to make the most out of remote learning with these practical tips. From creating a dedicated workspace to ensuring...
IoT Security in Cloud-Native Environments: Protecting Devices and Data
Discover the top security challenges of integrating IoT devices in cloud-native environments. Learn about offsite location risks, insurance coverage, and automated...
What You Need to Know About Extended Internet of Things (XIoT)
Discover the benefits and challenges of adopting the Extended Internet of Things (XIoT) in this comprehensive guide. Find out how XIoT...
Top 10 Container Orchestration Tools and Services
Access Docker Labs Containers are a popular way of packaging and deploying applications in a consistent and isolated manner. They offer...
A Comprehensive Guide to Dockerfile Linting with Hadolint
Learn how to improve your Dockerfile development with Hadolint. Discover how to install and use Hadolint, customize settings, and integrate with...
Latest Community-Curated Tutorials, Sample Apps, Events, and Videos | Collabnix Community Updates
Discover the latest community-curated tutorials, sample apps, events, and videos in the Collabnix Community. Submit your own content for inclusion in...
Effective Resource Management in Kubernetes: Requests, Limits, Allocation, and Monitoring
Learn how to effectively manage resources in Kubernetes. Set resource requests and limits, choose the appropriate resource type, allocate resources to...
Ways AI Can Be Used for Affiliate Marketing Success
Discover the role of Artificial Intelligence in affiliate marketing and how it can revolutionize your campaigns. Learn how AI tools can...
How to Set Up a PostgreSQL Replication Architecture Database in a Docker-Compose Environment
Learn how to set up a replication architecture database in a Docker environment using Docker-Compose. Scale your database efficiently for different...
How to Install a Kubernetes Cluster on CentOS 8
Learn how to install a Kubernetes cluster on CentOS 8 with this comprehensive guide. Harness the power of Kubernetes for containerized...
Highlights from Kubetools Day 2023: Demystifying the Landscape of Kubernetes
Discover the highlights of Kubetools Day at NMIT, a captivating event that brought together experts and enthusiasts in the containerization field....
Understanding Distributed Workers in BuildKit
Learn how distributed workers in BuildKit can optimize your Docker image builds. Discover the advantages of parallel execution, resource utilization, and...
Privacy-Preserving Smart Contracts: Bitcoin vs. Secret Network
Discover the world of privacy-preserving smart contracts as we compare Bitcoin and Secret Network. Learn how they handle privacy and security...
Understanding the Kubernetes Architecture: Control Plane, Nodes, and Components
Learn about Kubernetes architecture and its key components: control plane (kube-apiserver, kube-scheduler, kube-controller-manager, etcd) and nodes (kubelet, kube-proxy, container runtime, cAdvisor)....
Understanding Docker Build Cache
Discover how Docker caching works and its impact on image builds in this blog post. Learn how caching differs for ADD/COPY...
Containerd and Kubernetes: How are they related?
Discover how containers revolutionized application development and deployment, and how Kubernetes and Containerd simplify container management.
Kubetools Day Bengaluru: A Unique Show-n-Tell Event for Docker, Kubernetes, and AI Enthusiasts
Are you a tech enthusiast with a deep passion for Docker, Kubernetes, and the cutting-edge tools revolutionizing the AI ecosystem? Do...
CI/CD Tools for Streamlining Software Deployment
CI CD or Continuous integration and Continuous delivery processes are two integral parts of the software development lifecycle and DevOps testing....
Increase security with web application security testing
Explore the critical importance of web application security testing in our detailed article. Delve into the best practices, consequences of neglect,...
What is Docker Hub?
Unleash the power of containerization with Docker Hub, the essential guide for developers and enterprises. Discover features, benefits, and the vibrant...
What is eBPF? How it Works & Use Cases
Discover the power of eBPF, a technology that allows custom programs to run inside the Linux kernel without modifying its code....
Platform Engineering: The Future of DevOps and Software Delivery in 2024 and Beyond
Discover the rising star in software development: platform engineering. Learn why it's shaping the future of DevOps in 2024 and beyond....
Docker Desktop for Mac is no longer slow and how Docker Team fixed it
Docker Desktop for Mac was previously known to have performance issues, particularly with file system events and I/O operations. However, the...
Ollama vs. GPT: A Comparison of Language Models for AI Applications
The world of language models (LMs) is evolving at breakneck speed, with new names and capabilities emerging seemingly every day. For...
The Difference Between Citizen Developers and Professional Developers: Explained with Lego Analogy
Imagine you’re building a Lego castle. You have all the bricks you need, and you can put them together however you...
WSL Mirrored Mode Networking in Docker Desktop 4.26: Improved Communication and Development Workflow
Discover the new WSL mirrored mode networking in Docker Desktop 4.0! Simplify communication between WSL and Docker containers for improved development...
December Newsletter
Welcome to the Collabnix Monthly Newsletter! We bring you a curated list of latest community-curated tutorials, sample apps, events, and videos....
How To Run Containerd On Docker Desktop
Docker Desktop has become a ubiquitous tool for developers and IT professionals, offering a convenient and accessible platform for working with...
MindsDB Docker Extension: Build ML powered applications at a much faster pace
Imagine a world where anyone, regardless of technical expertise, can easily harness the power of artificial intelligence (AI) to gain insights...
Collabnix Monthly Newsletter – December 2023
Welcome to the Collabnix Monthly Newsletter! Get the latest community-curated tutorials, events, and more. Submit your own article or video for...
Ways to Pass Environment Variables to Docker Containers: -e Flag, .env File, and Docker Compose | Docker
Environment variables are the essential tools of any programmer’s toolkit. They hold settings, configurations, and secrets that shape how our applications...
Understanding HR Analytics and The Business Benefits It Brings
Business leaders made million-dollar decisions about their workforce for decades while flying blind. Hiring strategies, productivity investments, and retention programs –...
The Importance of Docker Container Backups: Best Practices and Strategies
Docker containers provide a flexible and scalable way to deploy applications, but ensuring the safety of your data is paramount. In...
Mastering MySQL Initialization in Docker: Techniques for Smooth Execution and Completion
Docker has revolutionized the way we deploy and manage applications, providing a consistent environment across various platforms. When working with MySQL...
Continuous Integration Unveiled: Building Quality Into Every Code Commit
Software development is a realm where innovation thrives and code evolves. Here, only one key player stands out. Do you know...
AI-powered Medical Document Summarization Made Possible using Docker GenAI Stack
As medical advisors in legal cases, sifting through mountains of complex medical documents is a daily reality. Unraveling medical jargon, deciphering...
How to Capture Screen Using Linux
Most content creators wonder how to make a video in 5 minutes and where to find reliable software for high-quality screen...
IoT Applications with SQL Server
In the dynamic realm of digital innovation, the Internet of Things (IoT) is a technological marvel that is reshaping our interaction...
Docker GenAI Stack on Windows using Docker Desktop
The Docker GenAI Stack repository, with nearly 2000 GitHub stars, is gaining traction among the data science community. It simplifies the...
How to change the default Disk Image Installation directory in Docker Desktop for Windows
Docker Desktop is a powerful tool that allows developers to build, ship, and run applications in containers. By default, Docker stores...
Getting Started With Containerd 2.0
Discover the benefits of Containerd, a software that runs and manages containers on Linux and Windows systems. Join our Slack Community...
TestContainers vs Docker: A Tale of Two Containers
Update: AtomicJar, a company behind testcontainers, is now a part of Docker Inc In the vibrant landscape of software development, containers...
How to Retrieve a Docker Container’s IP Address: Methods, Tools, and Scenarios
Docker, the ubiquitous containerization platform, has revolutionized the way we develop, deploy, and scale applications. One common challenge developers and administrators...
Docker ENTRYPOINT and CMD : Differences & Examples
Docker revolutionized the way we package and deploy applications, allowing developers to encapsulate their software into portable containers. Two critical Dockerfile...
Understanding the Relationship Between Machine Learning (ML), Deep Learning (DL), and Generative AI (GenAI)
Discover the intersection of Machine Learning (ML), Deep Learning (DL), and Generative AI (GenAI). Learn how GenAI leverages the strengths of...
PHP and Docker Init – Boost Your Development Workflow
Introducing docker init: the revolutionary command that simplifies Docker life for developers of all skill levels. Say goodbye to manual configuration...
How to Install and Run Ollama with Docker: A Beginner’s Guide
Let’s create our own local ChatGPT. In the rapidly evolving landscape of natural language processing, Ollama stands out as a game-changer,...
What’s New in Kubernetes 1.29: PersistentVolume Access Mode, Node Volume Expansion, KMS Encryption, Scheduler Optimization, and More
Kubernetes 1.29 draws inspiration from the intricate art form of Mandala, symbolizing the universe’s perfection. This theme reflects the interconnectedness of...
How To Automatically Update Docker Containers With Watchtower
Docker is a containerization tool used for packaging, distributing, and running applications in lightweight containers. However, manually updating containers across multiple...
Essential DevOps Brand Assets for Building a Strong Identity
Building a robust brand identity is crucial for any business, and for those immersed in the DevOps culture, maintaining consistency across...
Containerd Vs Docker: What’s the difference?
Discover the differences between Docker and containerd, and their roles in containerization. Learn about Docker as a versatile container development platform.
5 Benefits of Docker for the Finance and Operations
The dynamic world of finance and operations thrives on agility, efficiency, and resilience. Enter Docker, the game-changing containerization technology poised to...
Top 5 Kubernetes Backup and Storage Solutions: Velero and More
In a sample Kubernetes cluster as shown below, where you have your microservice application running and an elastic-search database also running...
Docker Scout for Your Kubernetes Cluster
Docker Scout is a collection of secure software supply chain capabilities that provide insights into the composition and security of container...
Collabnix: Docker, Kubernetes, and Cloud-Native Collaboration
In today’s technology-driven world, open-source projects have become the cornerstone of innovation and collaboration. Collabnix, a vibrant community of developers, DevOps...
Containerization Revolution: How Docker is Transforming SaaS Development
Join Our Slack Community In the ever-evolving landscape of software development, containerization has emerged as a revolutionary force, and at the...
Effortlessly manage Apache Kafka with Docker Compose: A YAML-powered guide!
Effortlessly Manage Kafka with Docker Compose: A YAML-Powered Guide!
Do You Need Expert Skills to Edit Photos Using CapCut Online Editor?
Many people get worried about how to make viral transformations to photos because of not have any expert photo editing skills....
How to Become a CNCF Ambassador and Join the Cloud-Native Community
The Cloud Native Computing Foundation (CNCF) has become a cornerstone in the world of cloud-native technologies, fostering innovation and collaboration within...
Choosing the Perfect Kubernetes Playground: A Comparison of PWD, Killercoda, and Other Options
Kubernetes is a powerful container orchestration platform, but its complexity can be daunting for beginners. Luckily, several online playgrounds offer a...
What is Containerd and what problems does it solve
Join Our Slack Community Containerd is the software responsible for managing and running containers on a host system; in other words,...
6 Ways to Adopt AI into Your Business
Join Our Slack Community The concept of intelligent machines has captivated human imagination for centuries. While Greek myths depicted mechanical men...
How to run Docker-Surfshark container for Secure and Private Internet Access
Join Our Slack Community To some of you, the idea of running a VPN inside a docker container might seem foreign,...
Optimizing Kubernetes for IoT and Edge Computing: Strategies for Seamless Deployment
The convergence of Kubernetes with IoT and Edge Computing has paved the way for a paradigm shift in how we manage...
The Role of Employee Onboarding Software in Talent Pipelines
Employee onboarding plays a vital role in attracting and retaining talent for organizations. It goes beyond getting employees up to speed;...
5 Tech Trends that Will Impact the Financial Services Sector
Join Our Slack Community The financial services industry is experiencing a swift evolution, with intelligent automation, AI-driven advisory, and asset management...
Ollama: A Lightweight, Extensible Framework for Building Language Models
Join Our Slack Community With over 10,00,000 Docker Pulls, Ollama is highly popular, lightweight, extensible framework for building and running language...
Docker Desktop 4.25.0: What’s New in Containerd
Join Our Slack Community This is a series of blog posts that discusses containerd feature support in all Docker Desktop releases....
Kubernetes Workshop for Beginners: Learn Core Concepts and Hands-On Exercises | Register Now
Join Our Slack Community Are you new to Kubernetes and looking to gain a solid understanding of its core concepts? Do...
DevOps and Paper Writing: How to Streamline Workflows for Technical Documentation
In the fast-paced world of technology, the need for clear and concise technical documentation has become paramount. Whether it’s user manuals,...
Bare Metal vs. VMs for Kubernetes: Performance Benchmarks
In the realm of container orchestration, Kubernetes reigns supreme, but the question of whether to deploy it on bare metal or...
Cloud and DevOps 2.0 x Docker Community Meetup
Join us for an exciting in-person meetup at Bengaluru as we bring everyone together to participate, collaborate, and share their knowledge...
Top 5 Storage Provider Tools for Kubernetes
Join Our Slack Community As Kubernetes keeps progressing, the need for storage management becomes crucial. The chosen storage provider tools in...
Navigating the Future: Emerging Trends in Cloud Technologies for Developing Cloud Applications
The latest advancements in technology have come a long way and have transformed business and its traditional ways. A forward-thinking step...
Understanding LLM Hallucination: Implications and Solutions for Large Language Models
Discover the world of large language models (LLMs) and their intriguing phenomenon of hallucination in artificial intelligence. Explore more in this...
Translate a Docker Compose File to Kubernetes Resources using Kompose
Docker Compose is a tool for defining and running multi-container Docker applications. It is a popular choice for developing and deploying...
The Internet of Things in Education: Definition, Role and Benefits
The power of the Internet in transforming the world is undeniable. The Internet of Things (IoT), which describes the connection of...
Unlocking Scalability and Resilience: Dapr on Kubernetes
Modernizing applications demands a new approach to distributed systems, and Dapr (Distributed Application Runtime) emerges as a robust solution. Dapr simplifies...
Top 5 Machine Learning Tools For Kubernetes
Join Our Slack Community Kubernetes is a platform that enables you to automate the process of deploying, scaling, and managing applications...
Foundation Vs Generative AI Model Demystified
In the realm of artificial intelligence, the terms "foundation AI model" and "generative AI model" are often used interchangeably, leading to...
Using AI To Fund Your Startup
Anyone would agree that the world has made more progress with artificial intelligence (AI) in the past year than in the...
Understanding the Role of Knowledge Management in an Organization
Knowledge management is akin to being the guide of shared intelligence within an organization. It goes beyond just collecting data; it’s...
Top 5 Alert and Monitoring Tools for Kubernetes
Kubernetes has emerged as the go-to choice for running applications in containers. It brings advantages compared to traditional deployment methods, like...
What is Python development: 7 major use cases
In the vast realm of programming languages, Python stands out as a powerhouse, renowned for its simplicity, versatility, and widespread adoption....
5 Most Interesting Announcements from Kubecon & CloudNativeCon North America 2023
KubeCon + CloudNativeCon North America 2023 was held in Chicago, Illinois, from November 6–9, 2023. It is the flagship conference of...
Top 5 Cluster Management Tools for Kubernetes in 2023
Kubernetes, also known as K8s, is a platform that allows you to efficiently manage your containerized applications across a group of...
10 Tips for Right Sizing Your Kubernetes Cluster
Kubernetes has become the de facto container orchestration platform for managing containerized applications at scale. However, ensuring that your Kubernetes cluster...
Top 5 Generative AI Challenges and Possible Solutions
Generative AI (GenAI) is a rapidly advancing field with the potential to revolutionize various industries and aspects of our lives. However,...
DevOps in the Real World: Making the World a Better Place
DevOps, short for Development and Operations, is not just a buzzword in the tech industry; it’s a transformative approach that's making...Benefits and Projects of the Cloud Native Computing Foundation (CNCF)
The Cloud Native Computing Foundation (CNCF) is a nonprofit organization that fosters the development, adoption, and sustainability of cloud native software....
What are Large Language Models: Popularity, Use Cases, and Case Studies
Unveiling LLMs: A Glimpse into Their Popularity, Versatile Use Cases, and Real-World Case Studies
Kubecon + CloudNativeCon North America 2023: A Must-Attend Event for Kubernetes Users
Kubecon + CloudNativeCon North America 2023 is the world’s largest Kubernetes conference, and it’s back in Chicago, Illinois from November 6-9,...
Architecting Kubernetes clusters- how many should you have
There are different ways to design Kubernetes clusters depending on the needs and objectives of users. Some common cluster architectures include:...
Generative AI: What It Is, Applications, and Impact
Generative AI is a type of artificial intelligence that can create new and original content, chat responses, designs, synthetic data, or...
Getting Started with Docker Desktop on Windows using WSL 2
Docker Desktop and WSL are two popular tools for developing and running containerized applications on Windows. Docker Desktop is a Docker...
The Impact of Big Data Development on Industries
The term "big data" is usually associated with companies like Google and Amazon, but the impact of big data development on...
Optimising Production Applications with Kubernetes: Tips for Deployment, Management and Scalability
Kubernetes is a container orchestration platform that automates many of the manual processes involved in deploying, managing, and scaling containerized applications....
Deploying ArgoCD with Amazon EKS
ArgoCD is a tool that helps integrate GitOps into your pipeline. The first thing to note is that ArgoCD does not...
Step-by-Step Guide to Deploying and Managing Redis on Kubernetes
Redis is a popular in-memory data structure store that is used by many applications for caching, messaging, and other tasks. It...
Legal Tech AI: How AI revolutionized the Practice of Law
As technologies rapidly evolve and seep into all domains of our lives, even the traditionally analog industries such as law are...
Introduction to KEDA – Automating Autoscaling in Kubernetes
Embarking on KEDA: A Guide to Kubernetes Event-Driven Autoscaling
Using Kubernetes and Slurm Together
Slurm is a job scheduler that is commonly used for managing high-performance computing (HPC) workloads. Kubernetes is a container orchestration platform...
WebAssembly: The Hottest Tech Whiz making Devs Dance!
In the fast-paced world of technology, a new star is born, and it’s got developers around the globe shaking their booties...
Budgeting for Success: Integrating DevOps into AAA-Game Production
DevOps is a new way of thinking about the relationship between development and operations. It’s not just about automating deployment, but...
How to Integrate Docker Scout with GitLab
GitLab is a DevOps platform that combines the functionality of a Git repository management system with continuous integration (CI) and continuous...
How The Adoption of Open Source Can Impact Mission-Critical Environments
Open source software – any software that is freely and available shared with others – has quickly become a staple in...
Docker Init for Go Developers
Are you a Go developer who still writes Dockerfile and Docker Compose manually? Containerizing Go applications is a crucial step towards...
What is Kubesphere and what problem does it solve
As a Kubernetes engineer, you likely have little trouble navigating around a Kubernetes cluster. Setting up resources, observing pod logs, and...
What is Docker Compose Include and What problem does it solve?
Docker Compose is a powerful tool for defining and running multi-container Docker applications. It enables you to manage complex applications with multiple...
Using FastAPI inside a Docker container
Discover the power of FastAPI for Python web development. Learn about its async-first design, automatic documentation, type hinting, performance, ecosystem, and...
Leveraging Compose Profiles for Dev, Prod, Test, and Staging Environments
Explore how Docker Compose Profiles revolutionize environment management in containerization. Simplify your workflows with this game-changing feature! #Docker #ContainerizationWhat is Hugging Face and why it is damn popular?
In the dynamic landscape of Natural Language Processing (NLP) and machine learning, one name stands out for its exceptional contributions and...
Docker Best Practices – Slim Images
Docker images are the building blocks of Docker containers. They are lightweight, executable packages of software that include everything needed to...
Docker vs Virtual Machine (VM) – Key Differences You Should Know
Let us understand this with a simple analogy. Virtual machines have a full OS with its own memory management installed with...
What a Career in Full Stack Development Looks Like
A career in full-stack development is both thrilling and dynamic. Full-stack developers wear many hats and are therefore invaluable to many...
Navigating Challenges in Cloud Migration with Consulting
Are you a business leader in the modern economy attempting to migrate data to cloud computing? Is it challenging for your...
The Best Paraphrasing Tools for Students in 2023
Plagiarism has made paraphrasing the immediate need of students these days. Submitting plagiarized assignments and papers will make you face excruciating...
OpenPubkey or SigStore – Which one to choose?
Container signing is a critical security practice for verifying the authenticity and integrity of containerized applications. It helps to ensure that...
What is Docker Compose Watch and what problem does it solve?
Quick Update: Docker Compose File Watch is no longer an experimental feature. I recommend you to either use the latest version...
Running Ollama 2 on NVIDIA Jetson Nano with GPU using Docker
Ollama is a rapidly growing development tool, with 10,000 Docker Hub pulls in a short period of time. It is a...
Future Trends in Retail Plan Software
The retail industry constantly evolves, driven by technological advancements and shifting consumer behaviors. To stay ahead of the curve, retailers must...
Getting Started with GenAI Stack powered with Docker, LangChain, Neo4j and Ollama
At DockerCon 2023, Docker announced a new GenAI Stack – a great way to quickly get started building GenAI-backed applications with...
Tech Tips for Students: Ace Research Papers
Academic life can be daunting, especially when it comes to writing research papers. However, in this technology-driven era, a plethora of...
10 Design Principles for Better Product Usability
When it comes to product usability, there are 10 key design principles that you should keep in mind when creating a...
Streamlining the Deal Making Process with Virtual Data Rooms
Today, we will look at the best data room providers and how they can optimize the business processes that take place...
CI/CD and AI Observability: A Comprehensive Guide for DevOps Teams
I. Introduction High-quality software solutions are now more important than ever in the fast-paced world of technology, especially where cloud infrastructure...
What is Resource Saver Mode in Docker Desktop and what problem does it solve?
Resource Saver mode is a new feature introduced in Docker Desktop 4.22 that allows you to conserve resources by reducing the...
How DevOps Skills Can Boost Job Opportunities for Students
In the rapidly evolving tech industry, acquiring relevant skills such as DevOps can significantly boost job opportunities for students. This skill...
5 Reasons to Like Linux: Beginner’s Introduction
Feeling a tad frustrated with the humdrum operating systems that have been holding you back? Or maybe you’re simply on the...
Docker for Data Science: Streamline Your Workflows and Collaboration
Data science is a dynamic field that revolves around experimentation, analysis, and model building. Data scientists often work with various libraries,...
Error message “cannot enable Hyper-V service” on Windows 10
Docker is a popular tool for building, running, and shipping containerized applications. However, some users may encounter the error message “cannot...